TP_ARGS( int, count, float, ratio, const char*, query )
The LTTng Documentation
Last update: 25 February 2021
Copyright © 2014-2021 The LTTng Project
This work is licensed under a Creative Commons Attribution 4.0 International License.
Warning:This version of the LTTng Documentation is not maintained anymore, since the corresponding version of LTTng is not the current release, nor the previous release.
Visit the latest LTTng Documentation version.
Welcome!
Welcome to the LTTng Documentation!
The Linux Trace Toolkit: next generation is an open source software toolkit which you can use to trace the Linux kernel, user applications, and user libraries at the same time.
LTTng consists of:
-
Kernel modules to trace the Linux kernel.
-
Shared libraries to trace C/C++ user applications.
-
Java packages to trace Java applications which use
java.util.loggingor Apache log4j 1.2. -
A Python package to trace Python applications which use the standard
loggingpackage. -
A kernel module to trace shell scripts and other user applications without a dedicated instrumentation mechanism.
-
Daemons and a command-line tool,
lttng, to control the LTTng tracers.
Open source documentation
Note:This is an open documentation: its source is available in a public Git repository.
Should you find any error in the content of this text, any grammatical mistake, or any dead link, we would be very grateful if you would file a GitHub issue for it or, even better, contribute a patch to this documentation by creating a pull request.
Target audience
The material of this documentation is appropriate for intermediate to advanced software developers working in a Linux environment and interested in efficient software tracing. LTTng is also worth a try for students interested in the inner mechanics of their systems.
If you do not have a programming background, you may wish to skip everything related to instrumentation, which often requires at least some programming language skills.
What’s in this documentation?
The LTTng Documentation is divided into the following sections:
-
Nuts and bolts explains the rudiments of software tracing and the rationale behind the LTTng project.
You can skip this section if you’re familiar with software tracing and with the LTTng project.
-
Installation describes the steps to install the LTTng packages on common Linux distributions and from their sources.
You can skip this section if you already properly installed LTTng on your target system.
-
Quick start is a concise guide to getting started quickly with LTTng kernel and user space tracing.
We recommend this section if you’re new to LTTng or to software tracing in general.
You can skip this section if you’re not new to LTTng.
-
Core concepts explains the concepts at the heart of LTTng.
It’s a good idea to become familiar with the core concepts before attempting to use the toolkit.
-
Components of LTTng describes the various components of the LTTng machinery, like the daemons, the libraries, and the command-line interface.
-
Instrumentation shows different ways to instrument user applications and the Linux kernel.
Instrumenting source code is essential to provide a meaningful source of events.
You can skip this section if you do not have a programming background.
-
Tracing control is divided into topics which demonstrate how to use the vast array of features that LTTng 2.10 offers.
-
Reference contains reference tables.
-
Glossary is a specialized dictionary of terms related to LTTng or to the field of software tracing.
Convention
Function names, parameter names, variable names, command names, argument
names, file system paths, file names, and other literal strings are
written using a monospace typeface in this document. An italic
word within such a block is a placeholder, usually described in the
following sentence.
Practical tips and notes are given throughout the document using the following style:
Tip:Read the tips.
Terminal boxes are used to show command lines:
$ #
echo Command line as a regular user echo Command line as a the `root` user
Command lines which you need to execute as a priviledged user start with
the # prompt or with sudo. Other command lines start with the $
prompt.
Acknowledgements
A few people made the online LTTng Documentation possible.
Philippe Proulx wrote most of the content, created the diagrams, and formatted the document. He’s the current maintainer of the LTTng Documentation.
Daniel U. Thibault, from the DRDC, wrote “LTTng: The Linux Trace Toolkit Next Generation — A Comprehensive User’s Guide (version 2.3 edition)” which was used to complete parts of the “Core concepts” and “Components of LTTng” sections and for a few passages here and there.
The entire EfficiOS team made essential reviews of the whole document.
We sincerely thank everyone who helped enhance the quality of this documentation.
What’s new in LTTng 2.10?
LTTng 2.10 bears the name KeKriek. From Brasserie Dunham, the KeKriek is a sour mashed golden wheat ale fermented with local sour cherries from Tougas orchards. Fresh sweet cherry notes with some tartness, lively carbonation with a dry finish.
New features and changes in LTTng 2.10:
-
Tracing control:
-
You can put more than one wildcard special character (
*), and not only at the end, when you create an event rule, in both the instrumentation point name and the literal strings of filter expressions:#
lttng enable-event --kernel 'x86_*_local_timer_*' \ --filter='name == "*a*b*c*d*e" && count >= 23'$
lttng enable-event --userspace '*_my_org:*msg*'
-
New trigger and notification API for
liblttng-ctl. This new subsystem allows you to register triggers which emit a notification when a given condition is satisfied. As of LTTng 2.10, only channel buffer usage conditions are available. Documentation is available in theliblttng-ctlheader files and in Get notified when a channel’s buffer usage is too high or too low. -
You can now embed the whole textual LTTng-tools man pages into the executables at build time with the
--enable-embedded-helpconfiguration option. Thanks to this option, you don’t need the AsciiDoc and xmlto tools at build time, and a manual pager at run time, to get access to this documentation.
-
-
User space tracing:
-
New blocking mode: an LTTng-UST tracepoint can now block until sub-buffer space is available instead of discarding event records in discard mode. With this feature, you can be sure that no event records are discarded during your application’s execution at the expense of performance.
For example, the following command lines create a user space tracing channel with an infinite blocking timeout and run an application instrumented with LTTng-UST which is explicitly allowed to block:
$ $ $ $ $
lttng create lttng enable-channel --userspace --blocking-timeout=inf blocking-channel lttng enable-event --userspace --channel=blocking-channel --all lttng start LTTNG_UST_ALLOW_BLOCKING=1 my-app
See the complete blocking timeout example.
-
-
Linux kernel tracing:
-
Linux 4.10, 4.11, and 4.12 support.
-
The thread state dump events recorded by LTTng-modules now contain the task’s CPU identifier. This improves the precision of the scheduler model for analyses.
-
Extended socketpair(2) system call tracing data.
-
Nuts and bolts
What is LTTng? As its name suggests, the Linux Trace Toolkit: next generation is a modern toolkit for tracing Linux systems and applications. So your first question might be: what is tracing?
What is tracing?
As the history of software engineering progressed and led to what we now take for granted—complex, numerous and interdependent software applications running in parallel on sophisticated operating systems like Linux—the authors of such components, software developers, began feeling a natural urge to have tools that would ensure the robustness and good performance of their masterpieces.
One major achievement in this field is, inarguably, the GNU debugger (GDB), an essential tool for developers to find and fix bugs. But even the best debugger won’t help make your software run faster, and nowadays, faster software means either more work done by the same hardware, or cheaper hardware for the same work.
A profiler is often the tool of choice to identify performance bottlenecks. Profiling is suitable to identify where performance is lost in a given software. The profiler outputs a profile, a statistical summary of observed events, which you may use to discover which functions took the most time to execute. However, a profiler won’t report why some identified functions are the bottleneck. Bottlenecks might only occur when specific conditions are met, conditions that are sometimes impossible to capture by a statistical profiler, or impossible to reproduce with an application altered by the overhead of an event-based profiler. For a thorough investigation of software performance issues, a history of execution is essential, with the recorded values of variables and context fields you choose, and with as little influence as possible on the instrumented software. This is where tracing comes in handy.
Tracing is a technique used to understand what goes on in a running software system. The software used for tracing is called a tracer, which is conceptually similar to a tape recorder. When recording, specific instrumentation points placed in the software source code generate events that are saved on a giant tape: a trace file. You can trace user applications and the operating system at the same time, opening the possibility of resolving a wide range of problems that would otherwise be extremely challenging.
Tracing is often compared to logging. However, tracers and loggers are two different tools, serving two different purposes. Tracers are designed to record much lower-level events that occur much more frequently than log messages, often in the range of thousands per second, with very little execution overhead. Logging is more appropriate for a very high-level analysis of less frequent events: user accesses, exceptional conditions (errors and warnings, for example), database transactions, instant messaging communications, and such. Simply put, logging is one of the many use cases that can be satisfied with tracing.
The list of recorded events inside a trace file can be read manually like a log file for the maximum level of detail, but it is generally much more interesting to perform application-specific analyses to produce reduced statistics and graphs that are useful to resolve a given problem. Trace viewers and analyzers are specialized tools designed to do this.
In the end, this is what LTTng is: a powerful, open source set of tools to trace the Linux kernel and user applications at the same time. LTTng is composed of several components actively maintained and developed by its community.
Alternatives to LTTng
Excluding proprietary solutions, a few competing software tracers exist for Linux:
-
dtrace4linux is a port of Sun Microsystems’s DTrace to Linux. The
dtracetool interprets user scripts and is responsible for loading code into the Linux kernel for further execution and collecting the outputted data. -
eBPF is a subsystem in the Linux kernel in which a virtual machine can execute programs passed from the user space to the kernel. You can attach such programs to tracepoints and KProbes thanks to a system call, and they can output data to the user space when executed thanks to different mechanisms (pipe, VM register values, and eBPF maps, to name a few).
-
ftrace is the de facto function tracer of the Linux kernel. Its user interface is a set of special files in sysfs.
-
perf is a performance analyzing tool for Linux which supports hardware performance counters, tracepoints, as well as other counters and types of probes. perf’s controlling utility is the
perfcommand line/curses tool. -
strace is a command-line utility which records system calls made by a user process, as well as signal deliveries and changes of process state. strace makes use of ptrace to fulfill its function.
-
sysdig, like SystemTap, uses scripts to analyze Linux kernel events. You write scripts, or chisels in sysdig’s jargon, in Lua and sysdig executes them while the system is being traced or afterwards. sysdig’s interface is the
sysdigcommand-line tool as well as the curses-basedcsysdigtool. -
SystemTap is a Linux kernel and user space tracer which uses custom user scripts to produce plain text traces. SystemTap converts the scripts to the C language, and then compiles them as Linux kernel modules which are loaded to produce trace data. SystemTap’s primary user interface is the
stapcommand-line tool.
The main distinctive features of LTTng is that it produces correlated kernel and user space traces, as well as doing so with the lowest overhead amongst other solutions. It produces trace files in the CTF format, a file format optimized for the production and analyses of multi-gigabyte data.
LTTng is the result of more than 10 years of active open source development by a community of passionate developers. LTTng 2.10 is currently available on major desktop and server Linux distributions.
The main interface for tracing control is a single command-line tool
named lttng. The latter can create several tracing sessions, enable
and disable events on the fly, filter events efficiently with custom
user expressions, start and stop tracing, and much more. LTTng can
record the traces on the file system or send them over the network, and
keep them totally or partially. You can view the traces once tracing
becomes inactive or in real-time.
Installation
Not available
Warning:The installation documentation for distributions is not available because this version of the LTTng Documentation is not maintained anymore.
Visit the latest LTTng Documentation version.
LTTng is a set of software components which interact to instrument the Linux kernel and user applications, and to control tracing (start and stop tracing, enable and disable event rules, and the rest). Those components are bundled into the following packages:
-
LTTng-tools: Libraries and command-line interface to control tracing.
-
LTTng-modules: Linux kernel modules to instrument and trace the kernel.
-
LTTng-UST: Libraries and Java/Python packages to instrument and trace user applications.
Most distributions mark the LTTng-modules and LTTng-UST packages as optional when installing LTTng-tools (which is always required). Note that:
-
You only need to install LTTng-modules if you intend to trace the Linux kernel.
-
You only need to install LTTng-UST if you intend to trace user applications.
Build from source
To build and install LTTng 2.10 from source:
-
Using your distribution’s package manager, or from source, install the following dependencies of LTTng-tools and LTTng-UST:
-
Download, build, and install the latest LTTng-modules 2.10:
$
cd $(mktemp -d) && wget http://lttng.org/files/lttng-modules/lttng-modules-latest-2.10.tar.bz2 && tar -xf lttng-modules-latest-2.10.tar.bz2 && cd lttng-modules-2.10.* && make && sudo make modules_install && sudo depmod -a
-
Download, build, and install the latest LTTng-UST 2.10:
$
cd $(mktemp -d) && wget http://lttng.org/files/lttng-ust/lttng-ust-latest-2.10.tar.bz2 && tar -xf lttng-ust-latest-2.10.tar.bz2 && cd lttng-ust-2.10.* && ./configure && make && sudo make install && sudo ldconfig
Java and Python application tracing
Important:If you need to instrument and trace Java applications, pass the
--enable-java-agent-jul,--enable-java-agent-log4j, or--enable-java-agent-alloptions to theconfigurescript, depending on which Java logging framework you use.If you need to instrument and trace Python applications, pass the
--enable-python-agentoption to theconfigurescript. You can set thePYTHONenvironment variable to the path to the Python interpreter for which to install the LTTng-UST Python agent package.Note:By default, LTTng-UST libraries are installed to
/usr/local/lib, which is the de facto directory in which to keep self-compiled and third-party libraries.When linking an instrumented user application with
liblttng-ust: -
Download, build, and install the latest LTTng-tools 2.10:
$
cd $(mktemp -d) && wget http://lttng.org/files/lttng-tools/lttng-tools-latest-2.10.tar.bz2 && tar -xf lttng-tools-latest-2.10.tar.bz2 && cd lttng-tools-2.10.* && ./configure && make && sudo make install && sudo ldconfig
Tip:The vlttng tool can do all the previous steps automatically for a given version of LTTng and confine the installed files in a specific directory. This can be useful to test LTTng without installing it on your system.
Quick start
This is a short guide to get started quickly with LTTng kernel and user space tracing.
Before you follow this guide, make sure to install LTTng.
This tutorial walks you through the steps to:
Trace the Linux kernel
The following command lines start with the # prompt because you need
root privileges to trace the Linux kernel. You can also trace the kernel
as a regular user if your Unix user is a member of the
tracing group.
-
Create a tracing session which writes its traces to
/tmp/my-kernel-trace:#
lttng create my-kernel-session --output=/tmp/my-kernel-trace
-
List the available kernel tracepoints and system calls:
# #
lttng list --kernel lttng list --kernel --syscall
-
Create event rules which match the desired instrumentation point names, for example the
sched_switchandsched_process_forktracepoints, and the open(2) and close(2) system calls:# #
lttng enable-event --kernel sched_switch,sched_process_fork lttng enable-event --kernel --syscall open,close
You can also create an event rule which matches all the Linux kernel tracepoints (this will generate a lot of data when tracing):
#
lttng enable-event --kernel --all
-
#
lttng start
-
Do some operation on your system for a few seconds. For example, load a website, or list the files of a directory.
-
Destroy the current tracing session:
#
lttng destroy
The lttng-destroy(1) command does not destroy the trace data; it only destroys the state of the tracing session.
The lttng-destroy(1) command also runs the lttng-stop(1) command implicitly (see Start and stop a tracing session). You need to stop tracing to make LTTng flush the remaining trace data and make the trace readable.
-
For the sake of this example, make the recorded trace accessible to the non-root users:
#
chown -R $(whoami) /tmp/my-kernel-trace
See View and analyze the recorded events to view the recorded events.
Trace a user application
This section steps you through a simple example to trace a Hello world program written in C.
To create the traceable user application:
-
Create the tracepoint provider header file, which defines the tracepoints and the events they can generate:
hello-tp.h#undef TRACEPOINT_PROVIDER #define TRACEPOINT_PROVIDER hello_world #undef TRACEPOINT_INCLUDE #define TRACEPOINT_INCLUDE "./hello-tp.h" #if !defined(_HELLO_TP_H) || defined(TRACEPOINT_HEADER_MULTI_READ) #define _HELLO_TP_H #include <lttng/tracepoint.h> TRACEPOINT_EVENT( hello_world, my_first_tracepoint, TP_ARGS( int, my_integer_arg, char*, my_string_arg ), TP_FIELDS( ctf_string(my_string_field, my_string_arg) ctf_integer(int, my_integer_field, my_integer_arg) ) ) #endif /* _HELLO_TP_H */ #include <lttng/tracepoint-event.h>
-
Create the tracepoint provider package source file:
hello-tp.c#define TRACEPOINT_CREATE_PROBES #define TRACEPOINT_DEFINE #include "hello-tp.h"
-
Build the tracepoint provider package:
$
gcc -c -I. hello-tp.c
-
Create the Hello World application source file:
hello.c#include <stdio.h> #include "hello-tp.h" int main(int argc, char *argv[]) { int x; puts("Hello, World!\nPress Enter to continue..."); /* * The following getchar() call is only placed here for the purpose * of this demonstration, to pause the application in order for * you to have time to list its tracepoints. It is not * needed otherwise. */ getchar(); /* * A tracepoint() call. * * Arguments, as defined in hello-tp.h: * * 1. Tracepoint provider name (required) * 2. Tracepoint name (required) * 3. my_integer_arg (first user-defined argument) * 4. my_string_arg (second user-defined argument) * * Notice the tracepoint provider and tracepoint names are * NOT strings: they are in fact parts of variables that the * macros in hello-tp.h create. */ tracepoint(hello_world, my_first_tracepoint, 23, "hi there!"); for (x = 0; x < argc; ++x) { tracepoint(hello_world, my_first_tracepoint, x, argv[x]); } puts("Quitting now!"); tracepoint(hello_world, my_first_tracepoint, x * x, "x^2"); return 0; }
-
Build the application:
$
gcc -c hello.c
-
Link the application with the tracepoint provider package,
liblttng-ust, andlibdl:$
gcc -o hello hello.o hello-tp.o -llttng-ust -ldl
Here’s the whole build process:

To trace the user application:
-
Run the application with a few arguments:
$
./hello world and beyond
You see:
Hello, World! Press Enter to continue...
-
Start an LTTng session daemon:
$
lttng-sessiond --daemonize
Note that a session daemon might already be running, for example as a service that the distribution’s service manager started.
-
List the available user space tracepoints:
$
lttng list --userspace
You see the
hello_world:my_first_tracepointtracepoint listed under the./helloprocess. -
Create a tracing session:
$
lttng create my-user-space-session
-
Create an event rule which matches the
hello_world:my_first_tracepointevent name:$
lttng enable-event --userspace hello_world:my_first_tracepoint
-
$
lttng start
-
Go back to the running
helloapplication and press Enter. The program executes alltracepoint()instrumentation points and exits. -
Destroy the current tracing session:
$
lttng destroy
The lttng-destroy(1) command does not destroy the trace data; it only destroys the state of the tracing session.
The lttng-destroy(1) command also runs the lttng-stop(1) command implicitly (see Start and stop a tracing session). You need to stop tracing to make LTTng flush the remaining trace data and make the trace readable.
By default, LTTng saves the traces in
$LTTNG_HOME/lttng-traces/name-date-time,
where name is the tracing session name. The
LTTNG_HOME environment variable defaults to $HOME if not set.
See View and analyze the recorded events to view the recorded events.
View and analyze the recorded events
Once you have completed the Trace the Linux kernel and Trace a user application tutorials, you can inspect the recorded events.
Many tools are available to read LTTng traces:
-
babeltraceis a command-line utility which converts trace formats; it supports the format that LTTng produces, CTF, as well as a basic text output which can begreped. Thebabeltracecommand is part of the Babeltrace project. -
Babeltrace also includes Python bindings so that you can easily open and read an LTTng trace with your own script, benefiting from the power of Python.
-
Trace Compass is a graphical user interface for viewing and analyzing any type of logs or traces, including LTTng’s.
-
LTTng analyses is a project which includes many high-level analyses of LTTng kernel traces, like scheduling statistics, interrupt frequency distribution, top CPU usage, and more.
Note:This section assumes that the traces recorded during the previous
tutorials were saved to their default location, in the
$LTTNG_HOME/lttng-traces directory. The LTTNG_HOME
environment variable defaults to $HOME if not set.
Use the babeltrace command-line tool
The simplest way to list all the recorded events of a trace is to pass
its path to babeltrace with no options:
$
babeltrace ~/lttng-traces/my-user-space-session*
babeltrace finds all traces recursively within the given path and
prints all their events, merging them in chronological order.
You can pipe the output of babeltrace into a tool like grep(1) for
further filtering:
$
babeltrace /tmp/my-kernel-trace | grep _switch
You can pipe the output of babeltrace into a tool like wc(1) to
count the recorded events:
$
babeltrace /tmp/my-kernel-trace | grep _open | wc --lines
Use the Babeltrace Python bindings
The text output of babeltrace
is useful to isolate events by simple matching using grep(1) and
similar utilities. However, more elaborate filters, such as keeping only
event records with a field value falling within a specific range, are
not trivial to write using a shell. Moreover, reductions and even the
most basic computations involving multiple event records are virtually
impossible to implement.
Fortunately, Babeltrace ships with Python 3 bindings which makes it easy to read the event records of an LTTng trace sequentially and compute the desired information.
The following script accepts an LTTng Linux kernel trace path as its first argument and prints the short names of the top 5 running processes on CPU 0 during the whole trace:
top5proc.py
from collections import Counter import babeltrace import sys def top5proc(): if len(sys.argv) != 2: msg = 'Usage: python3 {} TRACEPATH'.format(sys.argv[0]) print(msg, file=sys.stderr) return False # A trace collection contains one or more traces col = babeltrace.TraceCollection() # Add the trace provided by the user (LTTng traces always have # the 'ctf' format) if col.add_trace(sys.argv[1], 'ctf') is None: raise RuntimeError('Cannot add trace') # This counter dict contains execution times: # # task command name -> total execution time (ns) exec_times = Counter() # This contains the last `sched_switch` timestamp last_ts = None # Iterate on events for event in col.events: # Keep only `sched_switch` events if event.name != 'sched_switch': continue # Keep only events which happened on CPU 0 if event['cpu_id'] != 0: continue # Event timestamp cur_ts = event.timestamp if last_ts is None: # We start here last_ts = cur_ts # Previous task command (short) name prev_comm = event['prev_comm'] # Initialize entry in our dict if not yet done if prev_comm not in exec_times: exec_times[prev_comm] = 0 # Compute previous command execution time diff = cur_ts - last_ts # Update execution time of this command exec_times[prev_comm] += diff # Update last timestamp last_ts = cur_ts # Display top 5 for name, ns in exec_times.most_common(5): s = ns / 1000000000 print('{:20}{} s'.format(name, s)) return True if __name__ == '__main__': sys.exit(0 if top5proc() else 1)
Run this script:
$
python3 top5proc.py /tmp/my-kernel-trace/kernel
Output example:
swapper/0 48.607245889 s chromium 7.192738188 s pavucontrol 0.709894415 s Compositor 0.660867933 s Xorg.bin 0.616753786 s
Note that swapper/0 is the "idle" process of CPU 0 on Linux; since we
weren’t using the CPU that much when tracing, its first position in the
list makes sense.
Core concepts
From a user’s perspective, the LTTng system is built on a few concepts,
or objects, on which the lttng command-line tool
operates by sending commands to the session daemon.
Understanding how those objects relate to eachother is key in mastering
the toolkit.
The core concepts are:
Tracing session
A tracing session is a stateful dialogue between you and
a session daemon. You can
create a new tracing session with the lttng create command.
Anything that you do when you control LTTng tracers happens within a tracing session. In particular, a tracing session:
-
Has its own name.
-
Has its own set of trace files.
-
Has its own state of activity (started or stopped).
-
Has its own mode (local, network streaming, snapshot, or live).
-
Has its own channels which have their own event rules.
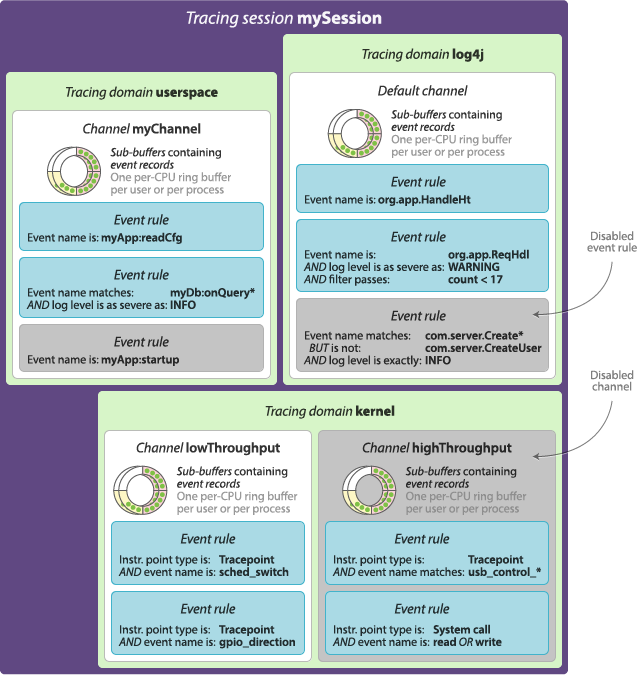
Those attributes and objects are completely isolated between different tracing sessions.
A tracing session is analogous to a cash machine session:
the operations you do on the banking system through the cash machine do
not alter the data of other users of the same system. In the case of
the cash machine, a session lasts as long as your bank card is inside.
In the case of LTTng, a tracing session lasts from the lttng create
command to the lttng destroy command.
Tracing session mode
LTTng can send the generated trace data to different locations. The tracing session mode dictates where to send it. The following modes are available in LTTng 2.10:
- Local mode
-
LTTng writes the traces to the file system of the machine being traced (target system).
- Network streaming mode
-
LTTng sends the traces over the network to a relay daemon running on a remote system.
- Snapshot mode
-
LTTng does not write the traces by default. Instead, you can request LTTng to take a snapshot, that is, a copy of the current tracing buffers, and to write it to the target’s file system or to send it over the network to a relay daemon running on a remote system.
- Live mode
-
This mode is similar to the network streaming mode, but a live trace viewer can connect to the distant relay daemon to view event records as LTTng generates them by the tracers.
Tracing domain
A tracing domain is a namespace for event sources. A tracing domain has its own properties and features.
There are currently five available tracing domains:
-
Linux kernel
-
User space
-
java.util.logging(JUL) -
log4j
-
Python
You must specify a tracing domain when using some commands to avoid ambiguity. For example, since all the domains support named tracepoints as event sources (instrumentation points that you manually insert in the source code), you need to specify a tracing domain when creating an event rule because all the tracing domains could have tracepoints with the same names.
Some features are reserved to specific tracing domains. Dynamic function entry and return instrumentation points, for example, are currently only supported in the Linux kernel tracing domain, but support for other tracing domains could be added in the future.
You can create channels in the Linux kernel and user space tracing domains. The other tracing domains have a single default channel.
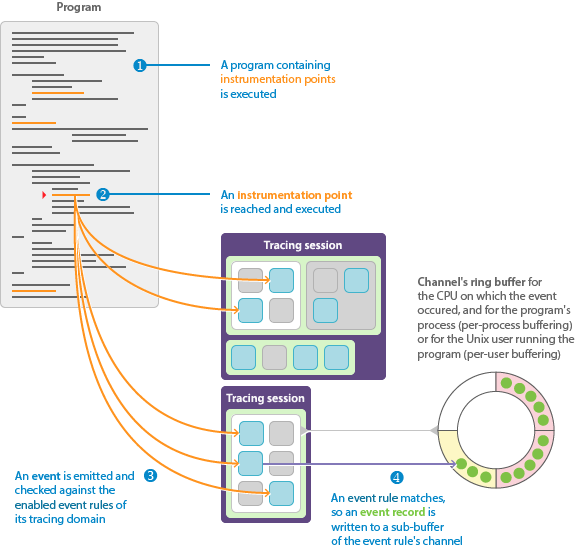
Channel and ring buffer
A channel is an object which is responsible for a set of ring buffers. Each ring buffer is divided into multiple sub-buffers. When an LTTng tracer emits an event, it can record it to one or more sub-buffers. The attributes of a channel determine what to do when there’s no space left for a new event record because all sub-buffers are full, where to send a full sub-buffer, and other behaviours.
A channel is always associated to a tracing domain. The
java.util.logging (JUL), log4j, and Python tracing domains each have
a default channel which you cannot configure.
A channel also owns event rules. When an LTTng tracer emits an event, it records it to the sub-buffers of all the enabled channels with a satisfied event rule, as long as those channels are part of active tracing sessions.
Per-user vs. per-process buffering schemes
A channel has at least one ring buffer per CPU. LTTng always records an event to the ring buffer associated to the CPU on which it occurred.
Two buffering schemes are available when you create a channel in the user space tracing domain:
- Per-user buffering
-
Allocate one set of ring buffers—one per CPU—shared by all the instrumented processes of each Unix user.
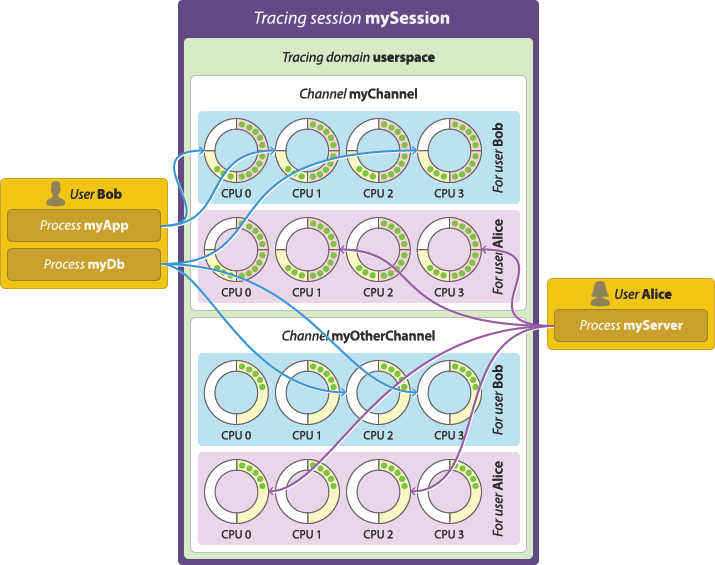
Per-user buffering scheme. - Per-process buffering
-
Allocate one set of ring buffers—one per CPU—for each instrumented process.
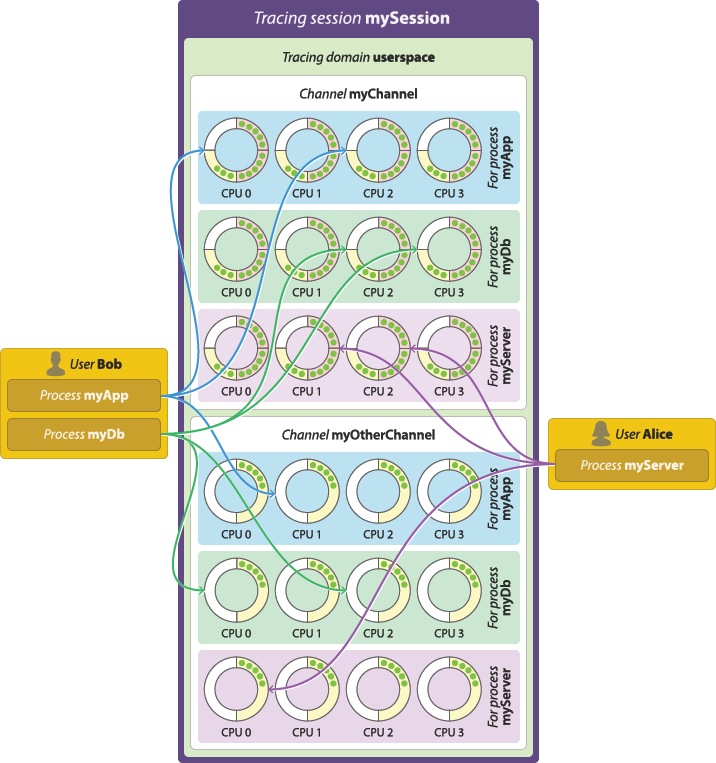
Per-process buffering scheme. The per-process buffering scheme tends to consume more memory than the per-user option because systems generally have more instrumented processes than Unix users running instrumented processes. However, the per-process buffering scheme ensures that one process having a high event throughput won’t fill all the shared sub-buffers of the same user, only its own.
The Linux kernel tracing domain has only one available buffering scheme which is to allocate a single set of ring buffers for the whole system. This scheme is similar to the per-user option, but with a single, global user "running" the kernel.
Overwrite vs. discard event loss modes
When an event occurs, LTTng records it to a specific sub-buffer (yellow arc in the following animation) of a specific channel’s ring buffer. When there’s no space left in a sub-buffer, the tracer marks it as consumable (red) and another, empty sub-buffer starts receiving the following event records. A consumer daemon eventually consumes the marked sub-buffer (returns to white).
In an ideal world, sub-buffers are consumed faster than they are filled, as is the case in the previous animation. In the real world, however, all sub-buffers can be full at some point, leaving no space to record the following events.
By default, LTTng-modules and LTTng-UST are non-blocking tracers: when no empty sub-buffer is available, it is acceptable to lose event records when the alternative would be to cause substantial delays in the instrumented application’s execution. LTTng privileges performance over integrity; it aims at perturbing the traced system as little as possible in order to make tracing of subtle race conditions and rare interrupt cascades possible.
Starting from LTTng 2.10, the LTTng user space tracer, LTTng-UST, supports a blocking mode. See the blocking timeout example to learn how to use the blocking mode.
When it comes to losing event records because no empty sub-buffer is available, or because the blocking timeout is reached, the channel’s event loss mode determines what to do. The available event loss modes are:
- Discard mode
-
Drop the newest event records until a the tracer releases a sub-buffer.
This is the only available mode when you specify a blocking timeout.
- Overwrite mode
-
Clear the sub-buffer containing the oldest event records and start writing the newest event records there.
This mode is sometimes called flight recorder mode because it’s similar to a flight recorder: always keep a fixed amount of the latest data.
Which mechanism you should choose depends on your context: prioritize the newest or the oldest event records in the ring buffer?
Beware that, in overwrite mode, the tracer abandons a whole sub-buffer as soon as a there’s no space left for a new event record, whereas in discard mode, the tracer only discards the event record that doesn’t fit.
In discard mode, LTTng increments a count of lost event records when an event record is lost and saves this count to the trace. Since LTTng 2.8, in overwrite mode, LTTng writes to a given sub-buffer its sequence number within its data stream. With a local, network streaming, or live tracing session, a trace reader can use such sequence numbers to report lost packets. In overwrite mode, LTTng doesn’t write to the trace the exact number of lost event records in those lost sub-buffers.
Trace analyses can use saved discarded event record and sub-buffer (packet) counts of the trace to decide whether or not to perform the analyses even if trace data is known to be missing.
There are a few ways to decrease your probability of losing event records. Sub-buffer count and size shows how you can fine-tune the sub-buffer count and size of a channel to virtually stop losing event records, though at the cost of greater memory usage.
Sub-buffer count and size
When you create a channel, you can set its number of sub-buffers and their size.
Note that there is noticeable CPU overhead introduced when switching sub-buffers (marking a full one as consumable and switching to an empty one for the following events to be recorded). Knowing this, the following list presents a few practical situations along with how to configure the sub-buffer count and size for them:
-
High event throughput: In general, prefer bigger sub-buffers to lower the risk of losing event records.
Having bigger sub-buffers also ensures a lower sub-buffer switching frequency.
The number of sub-buffers is only meaningful if you create the channel in overwrite mode: in this case, if a sub-buffer overwrite happens, the other sub-buffers are left unaltered.
-
Low event throughput: In general, prefer smaller sub-buffers since the risk of losing event records is low.
Because events occur less frequently, the sub-buffer switching frequency should remain low and thus the tracer’s overhead should not be a problem.
-
Low memory system: If your target system has a low memory limit, prefer fewer first, then smaller sub-buffers.
Even if the system is limited in memory, you want to keep the sub-buffers as big as possible to avoid a high sub-buffer switching frequency.
Note that LTTng uses CTF as its trace format, which means event data is very compact. For example, the average LTTng kernel event record weights about 32 bytes. Thus, a sub-buffer size of 1 MiB is considered big.
The previous situations highlight the major trade-off between a few big sub-buffers and more, smaller sub-buffers: sub-buffer switching frequency vs. how much data is lost in overwrite mode. Assuming a constant event throughput and using the overwrite mode, the two following configurations have the same ring buffer total size:
-
2 sub-buffers of 4 MiB each: Expect a very low sub-buffer switching frequency, but if a sub-buffer overwrite happens, half of the event records so far (4 MiB) are definitely lost.
-
8 sub-buffers of 1 MiB each: Expect 4 times the tracer’s overhead as the previous configuration, but if a sub-buffer overwrite happens, only the eighth of event records so far are definitely lost.
In discard mode, the sub-buffers count parameter is pointless: use two sub-buffers and set their size according to the requirements of your situation.
Switch timer period
The switch timer period is an important configurable attribute of a channel to ensure periodic sub-buffer flushing.
When the switch timer expires, a sub-buffer switch happens. You can set the switch timer period attribute when you create a channel to ensure that event data is consumed and committed to trace files or to a distant relay daemon periodically in case of a low event throughput.
This attribute is also convenient when you use big sub-buffers to cope with a sporadic high event throughput, even if the throughput is normally low.
Read timer period
By default, the LTTng tracers use a notification mechanism to signal a full sub-buffer so that a consumer daemon can consume it. When such notifications must be avoided, for example in real-time applications, you can use the channel’s read timer instead. When the read timer fires, the consumer daemon checks for full, consumable sub-buffers.
Trace file count and size
By default, trace files can grow as large as needed. You can set the maximum size of each trace file that a channel writes when you create a channel. When the size of a trace file reaches the channel’s fixed maximum size, LTTng creates another file to contain the next event records. LTTng appends a file count to each trace file name in this case.
If you set the trace file size attribute when you create a channel, the maximum number of trace files that LTTng creates is unlimited by default. To limit them, you can also set a maximum number of trace files. When the number of trace files reaches the channel’s fixed maximum count, the oldest trace file is overwritten. This mechanism is called trace file rotation.
Instrumentation point, event rule, event, and event record
An event rule is a set of conditions which must be all satisfied for LTTng to record an occuring event.
You set the conditions when you create an event rule.
You always attach an event rule to channel when you create it.
When an event passes the conditions of an event rule, LTTng records it in one of the attached channel’s sub-buffers.
The available conditions, as of LTTng 2.10, are:
-
The event rule is enabled.
-
The instrumentation point’s type is T.
-
The instrumentation point’s name (sometimes called event name) matches N, but is not E.
-
The instrumentation point’s log level is as severe as L, or is exactly L.
-
The fields of the event’s payload satisfy a filter expression F.
As you can see, all the conditions but the dynamic filter are related to the event rule’s status or to the instrumentation point, not to the occurring events. This is why, without a filter, checking if an event passes an event rule is not a dynamic task: when you create or modify an event rule, all the tracers of its tracing domain enable or disable the instrumentation points themselves once. This is possible because the attributes of an instrumentation point (type, name, and log level) are defined statically. In other words, without a dynamic filter, the tracer does not evaluate the arguments of an instrumentation point unless it matches an enabled event rule.
Note that, for LTTng to record an event, the channel to which a matching event rule is attached must also be enabled, and the tracing session owning this channel must be active.
Components of LTTng
The second T in LTTng stands for toolkit: it would be wrong to call LTTng a simple tool since it is composed of multiple interacting components. This section describes those components, explains their respective roles, and shows how they connect together to form the LTTng ecosystem.
The following diagram shows how the most important components of LTTng interact with user applications, the Linux kernel, and you:
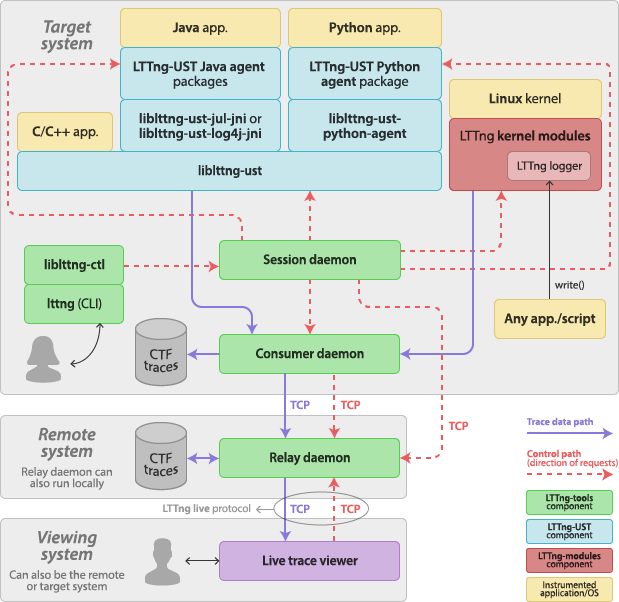
The LTTng project incorporates:
-
LTTng-tools: Libraries and command-line interface to control tracing sessions.
-
Consumer daemon (
lttng-consumerd). -
Tracing control library (
liblttng-ctl).
-
LTTng-UST: Libraries and Java/Python packages to trace user applications.
-
User space tracing library (
liblttng-ust) and its headers to instrument and trace any native user application. -
Preloadable user space tracing helpers:
-
liblttng-ust-libc-wrapper -
liblttng-ust-pthread-wrapper -
liblttng-ust-cyg-profile -
liblttng-ust-cyg-profile-fast -
liblttng-ust-dl
-
-
User space tracepoint provider source files generator command-line tool (lttng-gen-tp(1)).
-
LTTng-UST Java agent to instrument and trace Java applications using
java.util.loggingor Apache log4j 1.2 logging. -
LTTng-UST Python agent to instrument Python applications using the standard
loggingpackage.
-
-
LTTng-modules: Linux kernel modules to trace the kernel.
-
LTTng kernel tracer module.
-
Tracing ring buffer kernel modules.
-
Probe kernel modules.
-
LTTng logger kernel module.
-
Tracing control command-line interface

The lttng(1) command-line tool is the standard user interface to
control LTTng tracing sessions. The lttng tool
is part of LTTng-tools.
The lttng tool is linked with
liblttng-ctl to communicate with
one or more session daemons behind the scenes.
The lttng tool has a Git-like interface:
$
lttng <GENERAL OPTIONS> <COMMAND> <COMMAND OPTIONS>
The Tracing control section explores the
available features of LTTng using the lttng tool.
Tracing control library

The LTTng control library, liblttng-ctl, is used to communicate
with a session daemon using a C API that hides the
underlying protocol’s details. liblttng-ctl is part of LTTng-tools.
The lttng command-line tool
is linked with liblttng-ctl.
You can use liblttng-ctl in C or C++ source code by including its
"master" header:
#include <lttng/lttng.h>
Some objects are referenced by name (C string), such as tracing
sessions, but most of them require to create a handle first using
lttng_create_handle().
The best available developer documentation for liblttng-ctl is, as of
LTTng 2.10, its installed header files. Every function and
structure is thoroughly documented.
User space tracing library

The user space tracing library, liblttng-ust (see lttng-ust(3)),
is the LTTng user space tracer. It receives commands from a
session daemon, for example to
enable and disable specific instrumentation points, and writes event
records to ring buffers shared with a
consumer daemon.
liblttng-ust is part of LTTng-UST.
Public C header files are installed beside liblttng-ust to
instrument any C or C++ application.
LTTng-UST agents, which are regular Java and Python
packages, use their own library providing tracepoints which is
linked with liblttng-ust.
An application or library does not have to initialize liblttng-ust
manually: its constructor does the necessary tasks to properly register
to a session daemon. The initialization phase also enables the
instrumentation points matching the event rules that you
already created.
User space tracing agents
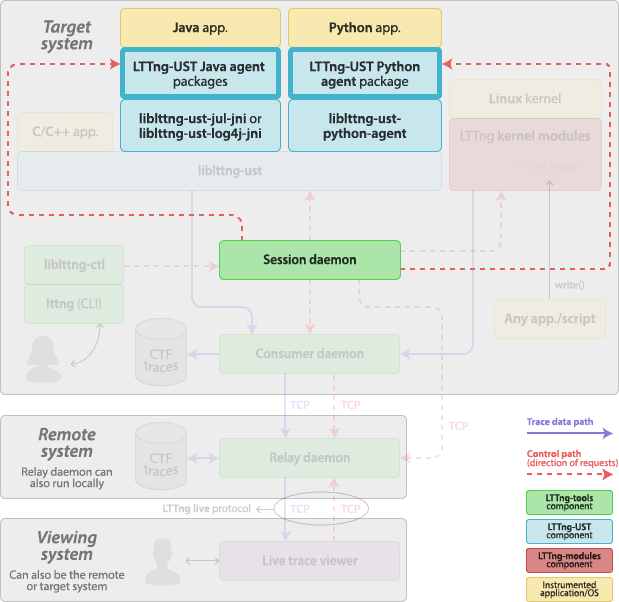
The LTTng-UST Java and Python agents are regular Java and Python packages which add LTTng tracing capabilities to the native logging frameworks. The LTTng-UST agents are part of LTTng-UST.
In the case of Java, the
java.util.logging
core logging facilities and
Apache log4j 1.2 are supported.
Note that Apache Log4 2 is not supported.
In the case of Python, the standard
logging package
is supported. Both Python 2 and Python 3 modules can import the
LTTng-UST Python agent package.
The applications using the LTTng-UST agents are in the
java.util.logging (JUL),
log4j, and Python tracing domains.
Both agents use the same mechanism to trace the log statements. When an
agent is initialized, it creates a log handler that attaches to the root
logger. The agent also registers to a session daemon.
When the application executes a log statement, it is passed to the
agent’s log handler by the root logger. The agent’s log handler calls a
native function in a tracepoint provider package shared library linked
with liblttng-ust, passing the formatted log message and
other fields, like its logger name and its log level. This native
function contains a user space instrumentation point, hence tracing the
log statement.
The log level condition of an event rule is considered when tracing a Java or a Python application, and it’s compatible with the standard JUL, log4j, and Python log levels.
LTTng kernel modules
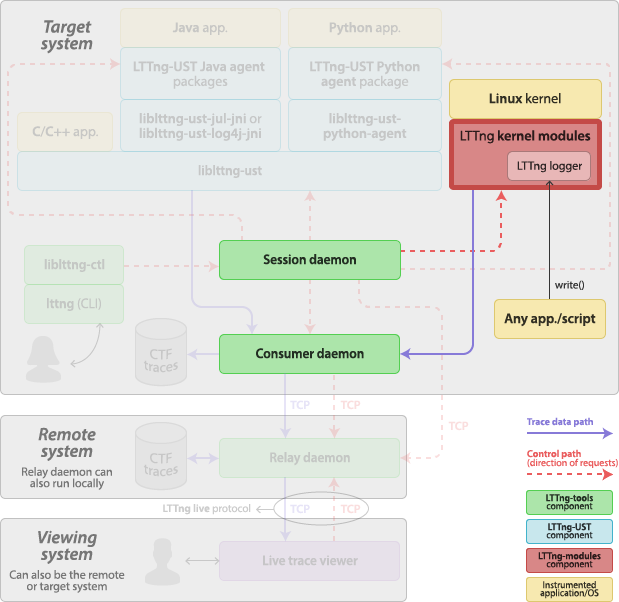
The LTTng kernel modules are a set of Linux kernel modules which implement the kernel tracer of the LTTng project. The LTTng kernel modules are part of LTTng-modules.
The LTTng kernel modules include:
-
A set of probe modules.
Each module attaches to a specific subsystem of the Linux kernel using its tracepoint instrument points. There are also modules to attach to the entry and return points of the Linux system call functions.
-
Ring buffer modules.
A ring buffer implementation is provided as kernel modules. The LTTng kernel tracer writes to the ring buffer; a consumer daemon reads from the ring buffer.
-
The LTTng kernel tracer module.
-
The LTTng logger module.
The LTTng logger module implements the special
/proc/lttng-loggerfile so that any executable can generate LTTng events by opening and writing to this file.See LTTng logger.
Generally, you do not have to load the LTTng kernel modules manually (using modprobe(8), for example): a root session daemon loads the necessary modules when starting. If you have extra probe modules, you can specify to load them to the session daemon on the command line.
The LTTng kernel modules are installed in
/usr/lib/modules/release/extra by default, where release is
the kernel release (see uname --kernel-release).
Session daemon
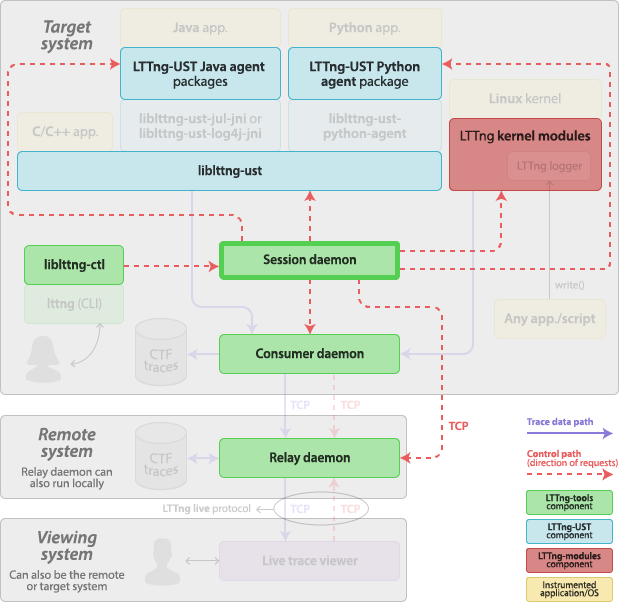
The session daemon, lttng-sessiond(8), is a daemon responsible for managing tracing sessions and for controlling the various components of LTTng. The session daemon is part of LTTng-tools.
The session daemon sends control requests to and receives control responses from:
-
The user space tracing library.
Any instance of the user space tracing library first registers to a session daemon. Then, the session daemon can send requests to this instance, such as:
-
Get the list of tracepoints.
-
Share an event rule so that the user space tracing library can enable or disable tracepoints. Amongst the possible conditions of an event rule is a filter expression which
liblttng-ustevalutes when an event occurs. -
Share channel attributes and ring buffer locations.
The session daemon and the user space tracing library use a Unix domain socket for their communication.
-
-
The user space tracing agents.
Any instance of a user space tracing agent first registers to a session daemon. Then, the session daemon can send requests to this instance, such as:
-
Get the list of loggers.
-
Enable or disable a specific logger.
The session daemon and the user space tracing agent use a TCP connection for their communication.
-
-
The LTTng kernel tracer.
-
The consumer daemon.
The session daemon sends requests to the consumer daemon to instruct it where to send the trace data streams, amongst other information.
-
The relay daemon.
The session daemon receives commands from the tracing control library.
The root session daemon loads the appropriate LTTng kernel modules on startup. It also spawns a consumer daemon as soon as you create an event rule.
The session daemon does not send and receive trace data: this is the role of the consumer daemon and relay daemon. It does, however, generate the CTF metadata stream.
Each Unix user can have its own session daemon instance. The tracing sessions managed by different session daemons are completely independent.
The root user’s session daemon is the only one which is allowed to control the LTTng kernel tracer, and its spawned consumer daemon is the only one which is allowed to consume trace data from the LTTng kernel tracer. Note, however, that any Unix user which is a member of the tracing group is allowed to create channels in the Linux kernel tracing domain, and thus to trace the Linux kernel.
The lttng command-line tool automatically starts a
session daemon when using its create command if none is currently
running. You can also start the session daemon manually.
Consumer daemon
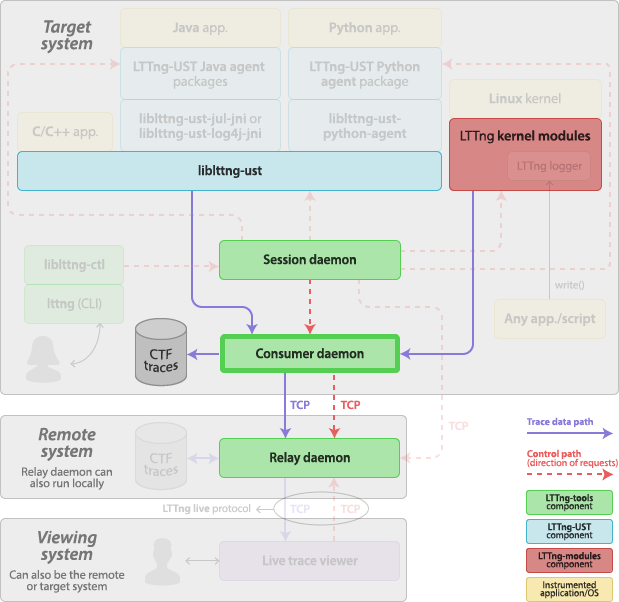
The consumer daemon, lttng-consumerd, is a daemon which shares
ring buffers with user applications or with the LTTng kernel modules to
collect trace data and send it to some location (on disk or to a
relay daemon over the network). The consumer daemon
is part of LTTng-tools.
You do not start a consumer daemon manually: a consumer daemon is always spawned by a session daemon as soon as you create an event rule, that is, before you start tracing. When you kill its owner session daemon, the consumer daemon also exits because it is the session daemon’s child process. Command-line options of lttng-sessiond(8) target the consumer daemon process.
There are up to two running consumer daemons per Unix user, whereas only one session daemon can run per user. This is because each process can be either 32-bit or 64-bit: if the target system runs a mixture of 32-bit and 64-bit processes, it is more efficient to have separate corresponding 32-bit and 64-bit consumer daemons. The root user is an exception: it can have up to three running consumer daemons: 32-bit and 64-bit instances for its user applications, and one more reserved for collecting kernel trace data.
Relay daemon
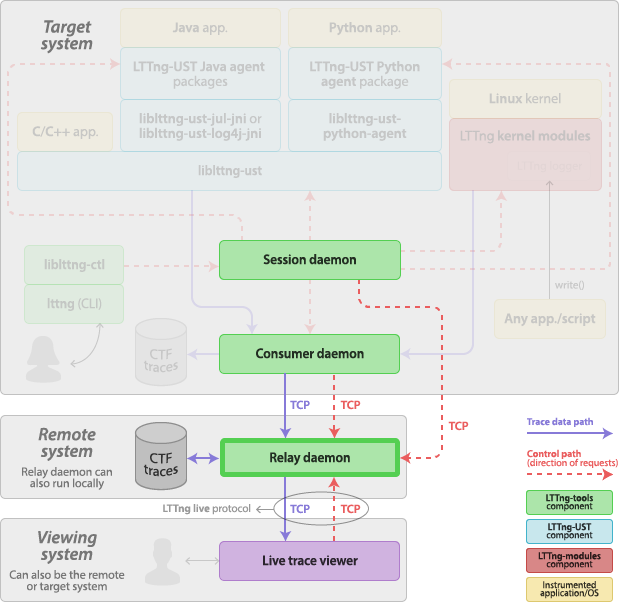
The relay daemon, lttng-relayd(8), is a daemon acting as a bridge between remote session and consumer daemons, local trace files, and a remote live trace viewer. The relay daemon is part of LTTng-tools.
The main purpose of the relay daemon is to implement a receiver of trace data over the network. This is useful when the target system does not have much file system space to record trace files locally.
The relay daemon is also a server to which a live trace viewer can connect. The live trace viewer sends requests to the relay daemon to receive trace data as the target system emits events. The communication protocol is named LTTng live; it is used over TCP connections.
Note that you can start the relay daemon on the target system directly. This is the setup of choice when the use case is to view events as the target system emits them without the need of a remote system.
Instrumentation
There are many examples of tracing and monitoring in our everyday life:
-
You have access to real-time and historical weather reports and forecasts thanks to weather stations installed around the country.
-
You know your heart is safe thanks to an electrocardiogram.
-
You make sure not to drive your car too fast and to have enough fuel to reach your destination thanks to gauges visible on your dashboard.
All the previous examples have something in common: they rely on instruments. Without the electrodes attached to the surface of your body’s skin, cardiac monitoring is futile.
LTTng, as a tracer, is no different from those real life examples. If you’re about to trace a software system or, in other words, record its history of execution, you better have instrumentation points in the subject you’re tracing, that is, the actual software.
Various ways were developed to instrument a piece of software for LTTng tracing. The most straightforward one is to manually place instrumentation points, called tracepoints, in the software’s source code. It is also possible to add instrumentation points dynamically in the Linux kernel tracing domain.
If you’re only interested in tracing the Linux kernel, your instrumentation needs are probably already covered by LTTng’s built-in Linux kernel tracepoints. You may also wish to trace a user application which is already instrumented for LTTng tracing. In such cases, you can skip this whole section and read the topics of the Tracing control section.
Many methods are available to instrument a piece of software for LTTng tracing. They are:
User space instrumentation for C and C++ applications
The procedure to instrument a C or C++ user application with
the LTTng user space tracing library, liblttng-ust, is:
If you need quick, printf(3)-like instrumentation, you can skip
those steps and use tracef() or tracelog()
instead.
Important:You need to install LTTng-UST to
instrument a user application with liblttng-ust.
Create the source files of a tracepoint provider package
A tracepoint provider is a set of compiled functions which provide
tracepoints to an application, the type of instrumentation point
supported by LTTng-UST. Those functions can emit events with
user-defined fields and serialize those events as event records to one
or more LTTng-UST channel sub-buffers. The tracepoint()
macro, which you insert in a user application’s source code, calls those functions.
A tracepoint provider package is an object file (.o) or a shared
library (.so) which contains one or more tracepoint providers.
Its source files are:
-
One or more tracepoint provider header (
.h).
A tracepoint provider package is dynamically linked with liblttng-ust,
the LTTng user space tracer, at run time.

liblttng-ust and containing a tracepoint provider.Note:If you need quick, printf(3)-like instrumentation, you can
skip creating and using a tracepoint provider and use
tracef() or tracelog() instead.
Create a tracepoint provider header file template
A tracepoint provider header file contains the tracepoint definitions of a tracepoint provider.
To create a tracepoint provider header file:
-
Start from this template:
Tracepoint provider header file template (
.hfile extension).#undef TRACEPOINT_PROVIDER #define TRACEPOINT_PROVIDER provider_name #undef TRACEPOINT_INCLUDE #define TRACEPOINT_INCLUDE "./tp.h" #if !defined(_TP_H) || defined(TRACEPOINT_HEADER_MULTI_READ) #define _TP_H #include <lttng/tracepoint.h> /* * Use TRACEPOINT_EVENT(), TRACEPOINT_EVENT_CLASS(), * TRACEPOINT_EVENT_INSTANCE(), and TRACEPOINT_LOGLEVEL() here. */ #endif /* _TP_H */ #include <lttng/tracepoint-event.h>
-
Replace:
-
provider_namewith the name of your tracepoint provider. -
"tp.h"with the name of your tracepoint provider header file.
-
-
Below the
#include <lttng/tracepoint.h>line, put your tracepoint definitions.
Your tracepoint provider name must be unique amongst all the possible
tracepoint provider names used on the same target system. We
suggest to include the name of your project or company in the name,
for example, org_lttng_my_project_tpp.
Tip:You can use the lttng-gen-tp(1) tool to create
this boilerplate for you. When using lttng-gen-tp, all you need to
write are the tracepoint definitions.
Create a tracepoint definition
A tracepoint definition defines, for a given tracepoint:
-
Its input arguments. They are the macro parameters that the
tracepoint()macro accepts for this particular tracepoint in the user application’s source code. -
Its output event fields. They are the sources of event fields that form the payload of any event that the execution of the
tracepoint()macro emits for this particular tracepoint.
You can create a tracepoint definition by using the
TRACEPOINT_EVENT() macro below the #include <lttng/tracepoint.h>
line in the
tracepoint provider header file template.
The syntax of the TRACEPOINT_EVENT() macro is:
TRACEPOINT_EVENT() macro syntax.
TRACEPOINT_EVENT( /* Tracepoint provider name */ provider_name, /* Tracepoint name */ tracepoint_name, /* Input arguments */ TP_ARGS( arguments ), /* Output event fields */ TP_FIELDS( fields ) )
Replace:
-
provider_namewith your tracepoint provider name. -
tracepoint_namewith your tracepoint name. -
argumentswith the input arguments. -
fieldswith the output event field definitions.
This tracepoint emits events named provider_name:tracepoint_name.
Event name’s length limitation
Important:The concatenation of the tracepoint provider name and the tracepoint name must not exceed 254 characters. If it does, the instrumented application compiles and runs, but LTTng throws multiple warnings and you could experience serious issues.
The syntax of the TP_ARGS() macro is:
TP_ARGS() macro syntax.
TP_ARGS( type, arg_name )
Replace:
-
typewith the C type of the argument. -
arg_namewith the argument name.
You can repeat type and arg_name up to 10 times to have
more than one argument.
Example:TP_ARGS() usage with three arguments.
The TP_ARGS() and TP_ARGS(void) forms are valid to create a
tracepoint definition with no input arguments.
The TP_FIELDS() macro contains a list of
ctf_*() macros. Each ctf_*() macro defines one event field. See
lttng-ust(3) for a complete description of the available ctf_*()
macros. A ctf_*() macro specifies the type, size, and byte order of
one event field.
Each ctf_*() macro takes an argument expression parameter. This is a
C expression that the tracer evalutes at the tracepoint() macro site
in the application’s source code. This expression provides a field’s
source of data. The argument expression can include input argument names
listed in the TP_ARGS() macro.
Each ctf_*() macro also takes a field name parameter. Field names
must be unique within a given tracepoint definition.
Here’s a complete tracepoint definition example:
Example:Tracepoint definition.
The following tracepoint definition defines a tracepoint which takes three input arguments and has four output event fields.
#include "my-custom-structure.h" TRACEPOINT_EVENT( my_provider, my_tracepoint, TP_ARGS( const struct my_custom_structure*, my_custom_structure, float, ratio, const char*, query ), TP_FIELDS( ctf_string(query_field, query) ctf_float(double, ratio_field, ratio) ctf_integer(int, recv_size, my_custom_structure->recv_size) ctf_integer(int, send_size, my_custom_structure->send_size) ) )
You can refer to this tracepoint definition with the tracepoint()
macro in your application’s source code like this:
tracepoint(my_provider, my_tracepoint, my_structure, some_ratio, the_query);
Note:The LTTng tracer only evaluates tracepoint arguments at run time if they satisfy an enabled event rule.
Use a tracepoint class
A tracepoint class is a class of tracepoints which share the same output event field definitions. A tracepoint instance is one instance of such a defined tracepoint class, with its own tracepoint name.
The TRACEPOINT_EVENT() macro is actually a
shorthand which defines both a tracepoint class and a tracepoint
instance at the same time.
When you build a tracepoint provider package, the C or C++ compiler creates one serialization function for each tracepoint class. A serialization function is responsible for serializing the event fields of a tracepoint to a sub-buffer when tracing.
For various performance reasons, when your situation requires multiple tracepoint definitions with different names, but with the same event fields, we recommend that you manually create a tracepoint class and instantiate as many tracepoint instances as needed. One positive effect of such a design, amongst other advantages, is that all tracepoint instances of the same tracepoint class reuse the same serialization function, thus reducing cache pollution.
Example:Use a tracepoint class and tracepoint instances.
Consider the following three tracepoint definitions:
TRACEPOINT_EVENT( my_app, get_account, TP_ARGS( int, userid, size_t, len ), TP_FIELDS( ctf_integer(int, userid, userid) ctf_integer(size_t, len, len) ) ) TRACEPOINT_EVENT( my_app, get_settings, TP_ARGS( int, userid, size_t, len ), TP_FIELDS( ctf_integer(int, userid, userid) ctf_integer(size_t, len, len) ) ) TRACEPOINT_EVENT( my_app, get_transaction, TP_ARGS( int, userid, size_t, len ), TP_FIELDS( ctf_integer(int, userid, userid) ctf_integer(size_t, len, len) ) )
In this case, we create three tracepoint classes, with one implicit
tracepoint instance for each of them: get_account, get_settings, and
get_transaction. However, they all share the same event field names
and types. Hence three identical, yet independent serialization
functions are created when you build the tracepoint provider package.
A better design choice is to define a single tracepoint class and three tracepoint instances:
/* The tracepoint class */ TRACEPOINT_EVENT_CLASS( /* Tracepoint provider name */ my_app, /* Tracepoint class name */ my_class, /* Input arguments */ TP_ARGS( int, userid, size_t, len ), /* Output event fields */ TP_FIELDS( ctf_integer(int, userid, userid) ctf_integer(size_t, len, len) ) ) /* The tracepoint instances */ TRACEPOINT_EVENT_INSTANCE( /* Tracepoint provider name */ my_app, /* Tracepoint class name */ my_class, /* Tracepoint name */ get_account, /* Input arguments */ TP_ARGS( int, userid, size_t, len ) ) TRACEPOINT_EVENT_INSTANCE( my_app, my_class, get_settings, TP_ARGS( int, userid, size_t, len ) ) TRACEPOINT_EVENT_INSTANCE( my_app, my_class, get_transaction, TP_ARGS( int, userid, size_t, len ) )
Assign a log level to a tracepoint definition
You can assign an optional log level to a tracepoint definition.
Assigning different levels of severity to tracepoint definitions can be useful: when you create an event rule, you can target tracepoints having a log level as severe as a specific value.
The concept of LTTng-UST log levels is similar to the levels found in typical logging frameworks:
-
In a logging framework, the log level is given by the function or method name you use at the log statement site:
debug(),info(),warn(),error(), and so on. -
In LTTng-UST, you statically assign the log level to a tracepoint definition; any
tracepoint()macro invocation which refers to this definition has this log level.
You can assign a log level to a tracepoint definition with the
TRACEPOINT_LOGLEVEL() macro. You must use this macro after the
TRACEPOINT_EVENT() or
TRACEPOINT_INSTANCE() macro for a given
tracepoint.
The syntax of the TRACEPOINT_LOGLEVEL() macro is:
TRACEPOINT_LOGLEVEL() macro syntax.
TRACEPOINT_LOGLEVEL(provider_name, tracepoint_name, log_level)
Replace:
-
provider_namewith the tracepoint provider name. -
tracepoint_namewith the tracepoint name. -
log_levelwith the log level to assign to the tracepoint definition namedtracepoint_namein theprovider_nametracepoint provider.See lttng-ust(3) for a list of available log level names.
Example:Assign the TRACE_DEBUG_UNIT log level to a tracepoint definition.
/* Tracepoint definition */ TRACEPOINT_EVENT( my_app, get_transaction, TP_ARGS( int, userid, size_t, len ), TP_FIELDS( ctf_integer(int, userid, userid) ctf_integer(size_t, len, len) ) ) /* Log level assignment */ TRACEPOINT_LOGLEVEL(my_app, get_transaction, TRACE_DEBUG_UNIT)
Create a tracepoint provider package source file
A tracepoint provider package source file is a C source file which includes a tracepoint provider header file to expand its macros into event serialization and other functions.
You can always use the following tracepoint provider package source file template:
Tracepoint provider package source file template.
#define TRACEPOINT_CREATE_PROBES #include "tp.h"
Replace tp.h with the name of your tracepoint provider header file name. You may also include more than one tracepoint
provider header file here to create a tracepoint provider package
holding more than one tracepoint providers.
Add tracepoints to an application’s source code
Once you create a tracepoint provider header file, you
can use the tracepoint() macro in your application’s
source code to insert the tracepoints that this header
defines.
The tracepoint() macro takes at least two parameters: the tracepoint
provider name and the tracepoint name. The corresponding tracepoint
definition defines the other parameters.
Example:tracepoint() usage.
The following tracepoint definition defines a tracepoint which takes two input arguments and has two output event fields.
Tracepoint provider header file.
#include "my-custom-structure.h" TRACEPOINT_EVENT( my_provider, my_tracepoint, TP_ARGS( int, argc, const char*, cmd_name ), TP_FIELDS( ctf_string(cmd_name, cmd_name) ctf_integer(int, number_of_args, argc) ) )
You can refer to this tracepoint definition with the tracepoint()
macro in your application’s source code like this:
Application’s source file.
#include "tp.h" int main(int argc, char* argv[]) { tracepoint(my_provider, my_tracepoint, argc, argv[0]); return 0; }
Note how the application’s source code includes
the tracepoint provider header file containing the tracepoint
definitions to use, tp.h.
Example:tracepoint() usage with a complex tracepoint definition.
Consider this complex tracepoint definition, where multiple event fields refer to the same input arguments in their argument expression parameter:
Tracepoint provider header file.
/* For `struct stat` */ #include <sys/types.h> #include <sys/stat.h> #include <unistd.h> TRACEPOINT_EVENT( my_provider, my_tracepoint, TP_ARGS( int, my_int_arg, char*, my_str_arg, struct stat*, st ), TP_FIELDS( ctf_integer(int, my_constant_field, 23 + 17) ctf_integer(int, my_int_arg_field, my_int_arg) ctf_integer(int, my_int_arg_field2, my_int_arg * my_int_arg) ctf_integer(int, sum4_field, my_str_arg[0] + my_str_arg[1] + my_str_arg[2] + my_str_arg[3]) ctf_string(my_str_arg_field, my_str_arg) ctf_integer_hex(off_t, size_field, st->st_size) ctf_float(double, size_dbl_field, (double) st->st_size) ctf_sequence_text(char, half_my_str_arg_field, my_str_arg, size_t, strlen(my_str_arg) / 2) ) )
You can refer to this tracepoint definition with the tracepoint()
macro in your application’s source code like this:
Application’s source file.
#define TRACEPOINT_DEFINE #include "tp.h" int main(void) { struct stat s; stat("/etc/fstab", &s); tracepoint(my_provider, my_tracepoint, 23, "Hello, World!", &s); return 0; }
If you look at the event record that LTTng writes when tracing this
program, assuming the file size of /etc/fstab is 301 bytes,
it should look like this:
Event record fields
| Field’s name | Field’s value |
|---|---|
| 40 |
| 23 |
| 529 |
| 389 |
|
|
| 0x12d |
| 301.0 |
|
|
Sometimes, the arguments you pass to tracepoint() are expensive to
compute—they use the call stack, for example. To avoid this
computation when the tracepoint is disabled, you can use the
tracepoint_enabled() and do_tracepoint() macros.
The syntax of the tracepoint_enabled() and do_tracepoint() macros
is:
tracepoint_enabled() and do_tracepoint() macros syntax.
tracepoint_enabled(provider_name, tracepoint_name) do_tracepoint(provider_name, tracepoint_name, ...)
Replace:
-
provider_namewith the tracepoint provider name. -
tracepoint_namewith the tracepoint name.
tracepoint_enabled() returns a non-zero value if the tracepoint named
tracepoint_name from the provider named provider_name is enabled
at run time.
do_tracepoint() is like tracepoint(), except that it doesn’t check
if the tracepoint is enabled. Using tracepoint() with
tracepoint_enabled() is dangerous since tracepoint() also contains
the tracepoint_enabled() check, thus a race condition is
possible in this situation:
Possible race condition when using tracepoint_enabled() with tracepoint().
if (tracepoint_enabled(my_provider, my_tracepoint)) { stuff = prepare_stuff(); } tracepoint(my_provider, my_tracepoint, stuff);
If the tracepoint is enabled after the condition, then stuff is not
prepared: the emitted event will either contain wrong data, or the whole
application could crash (segmentation fault, for example).
Note:Neither tracepoint_enabled() nor do_tracepoint() have an
STAP_PROBEV() call. If you need it, you must emit
this call yourself.
Build and link a tracepoint provider package and an application
Once you have one or more tracepoint provider header files and a tracepoint provider package source file, you can create the tracepoint provider package by compiling its source file. From here, multiple build and run scenarios are possible. The following table shows common application and library configurations along with the required command lines to achieve them.
In the following diagrams, we use the following file names:
-
app -
Executable application.
-
app.o -
Application’s object file.
-
tpp.o -
Tracepoint provider package object file.
-
tpp.a -
Tracepoint provider package archive file.
-
libtpp.so -
Tracepoint provider package shared object file.
-
emon.o -
User library object file.
-
libemon.so -
User library shared object file.
We use the following symbols in the diagrams of table below:

We assume that . is part of the LD_LIBRARY_PATH environment
variable in the following instructions.
Common tracepoint provider package scenarios.
| Scenario | Instructions |
|---|---|
The instrumented application is statically linked with the tracepoint provider package object.  | To build the tracepoint provider package object file:
To build the instrumented application:
To run the instrumented application:
|
The instrumented application is statically linked with the tracepoint provider package archive file.  | To create the tracepoint provider package archive file:
To build the instrumented application:
To run the instrumented application:
|
The instrumented application is linked with the tracepoint provider package shared object.  | To build the tracepoint provider package shared object:
To build the instrumented application:
To run the instrumented application:
|
The tracepoint provider package shared object is preloaded before the instrumented application starts. 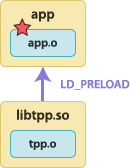 | To build the tracepoint provider package shared object:
To build the instrumented application:
To run the instrumented application with tracing support:
To run the instrumented application without tracing support:
|
The instrumented application dynamically loads the tracepoint provider package shared object. See the warning about 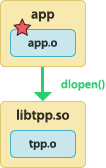 | To build the tracepoint provider package shared object:
To build the instrumented application:
To run the instrumented application:
|
The application is linked with the instrumented user library. The instrumented user library is statically linked with the tracepoint provider package object file. 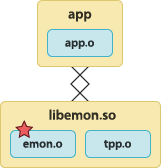 | To build the tracepoint provider package object file:
To build the instrumented user library:
To build the application:
To run the application:
|
The application is linked with the instrumented user library. The instrumented user library is linked with the tracepoint provider package shared object. 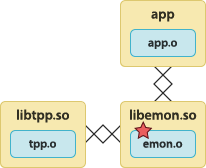 | To build the tracepoint provider package shared object:
To build the instrumented user library:
To build the application:
To run the application:
|
The tracepoint provider package shared object is preloaded before the application starts. The application is linked with the instrumented user library. 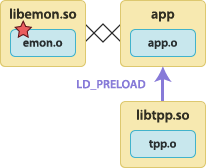 | To build the tracepoint provider package shared object:
To build the instrumented user library:
To build the application:
To run the application with tracing support:
To run the application without tracing support:
|
The application is linked with the instrumented user library. The instrumented user library dynamically loads the tracepoint provider package shared object. See the warning about 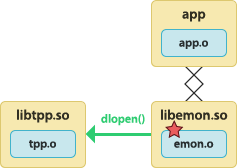 | To build the tracepoint provider package shared object:
To build the instrumented user library:
To build the application:
To run the application:
|
The application dynamically loads the instrumented user library. The instrumented user library is linked with the tracepoint provider package shared object. See the warning about  | To build the tracepoint provider package shared object:
To build the instrumented user library:
To build the application:
To run the application:
|
The application dynamically loads the instrumented user library. The instrumented user library dynamically loads the tracepoint provider package shared object. See the warning about 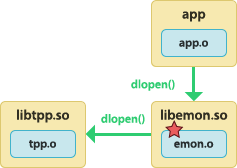 | To build the tracepoint provider package shared object:
To build the instrumented user library:
To build the application:
To run the application:
|
The tracepoint provider package shared object is preloaded before the application starts. The application dynamically loads the instrumented user library. 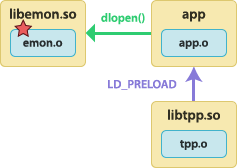 | To build the tracepoint provider package shared object:
To build the instrumented user library:
To build the application:
To run the application with tracing support:
To run the application without tracing support:
|
The application is statically linked with the tracepoint provider package object file. The application is linked with the instrumented user library. 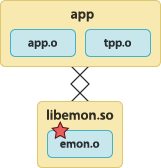 | To build the tracepoint provider package object file:
To build the instrumented user library:
To build the application:
To run the instrumented application:
|
The application is statically linked with the tracepoint provider package object file. The application dynamically loads the instrumented user library. 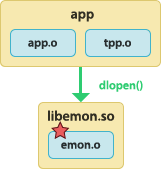 | To build the tracepoint provider package object file:
To build the application:
To build the instrumented user library:
To run the application:
|
Do not use dlclose(3) on a tracepoint provider package
Important:Never use dlclose(3) on any shared object which:
-
Is linked with, statically or dynamically, a tracepoint provider package.
-
Calls dlopen(3) itself to dynamically open a tracepoint provider package shared object.
This is currently considered unsafe due to a lack of reference counting from LTTng-UST to the shared object.
A known workaround (available since glibc 2.2) is to use the
RTLD_NODELETE flag when calling dlopen(3) initially. This has the
effect of not unloading the loaded shared object, even if dlclose(3)
is called.
You can also preload the tracepoint provider package shared object with
the LD_PRELOAD environment variable to overcome this limitation.
Use LTTng-UST with daemons
If your instrumented application calls fork(2), clone(2),
or BSD’s rfork(2), without a following exec(3)-family
system call, you must preload the liblttng-ust-fork.so shared
object when you start the application.
$
LD_PRELOAD=liblttng-ust-fork.so ./my-app
If your tracepoint provider package is
a shared library which you also preload, you must put both
shared objects in LD_PRELOAD:
$
LD_PRELOAD=liblttng-ust-fork.so:/path/to/tp.so ./my-app
Use LTTng-UST with applications which close file descriptors that don’t belong to them
Since 2.9
If your instrumented application closes one or more file descriptors
which it did not open itself, you must preload the
liblttng-ust-fd.so shared object when you start the application:
$
LD_PRELOAD=liblttng-ust-fd.so ./my-app
Typical use cases include closing all the file descriptors after fork(2) or rfork(2) and buggy applications doing “double closes”.
Use pkg-config
On some distributions, LTTng-UST ships with a
pkg-config
metadata file. If this is your case, then you can use pkg-config to
build an application on the command line:
$
gcc -o my-app my-app.o tp.o $(pkg-config --cflags --libs lttng-ust)
Build a 32-bit instrumented application for a 64-bit target system
In order to trace a 32-bit application running on a 64-bit system, LTTng must use a dedicated 32-bit consumer daemon.
The following steps show how to build and install a 32-bit consumer daemon, which is not part of the default 64-bit LTTng build, how to build and install the 32-bit LTTng-UST libraries, and how to build and link an instrumented 32-bit application in that context.
To build a 32-bit instrumented application for a 64-bit target system, assuming you have a fresh target system with no installed Userspace RCU or LTTng packages:
-
Download, build, and install a 32-bit version of Userspace RCU:
$
cd $(mktemp -d) && wget http://lttng.org/files/urcu/userspace-rcu-latest-0.9.tar.bz2 && tar -xf userspace-rcu-latest-0.9.tar.bz2 && cd userspace-rcu-0.9.* && ./configure --libdir=/usr/local/lib32 CFLAGS=-m32 && make && sudo make install && sudo ldconfig
-
Using your distribution’s package manager, or from source, install the following 32-bit versions of the following dependencies of LTTng-tools and LTTng-UST:
-
Download, build, and install a 32-bit version of the latest LTTng-UST 2.10:
$
cd $(mktemp -d) && wget http://lttng.org/files/lttng-ust/lttng-ust-latest-2.10.tar.bz2 && tar -xf lttng-ust-latest-2.10.tar.bz2 && cd lttng-ust-2.10.* && ./configure --libdir=/usr/local/lib32 \ CFLAGS=-m32 CXXFLAGS=-m32 \ LDFLAGS='-L/usr/local/lib32 -L/usr/lib32' && make && sudo make install && sudo ldconfigNote:Depending on your distribution, 32-bit libraries could be installed at a different location than
/usr/lib32. For example, Debian is known to install some 32-bit libraries in/usr/lib/i386-linux-gnu.In this case, make sure to set
LDFLAGSto all the relevant 32-bit library paths, for example:$
LDFLAGS='-L/usr/lib/i386-linux-gnu -L/usr/lib32'
-
Download the latest LTTng-tools 2.10, build, and install the 32-bit consumer daemon:
$
cd $(mktemp -d) && wget http://lttng.org/files/lttng-tools/lttng-tools-latest-2.10.tar.bz2 && tar -xf lttng-tools-latest-2.10.tar.bz2 && cd lttng-tools-2.10.* && ./configure --libdir=/usr/local/lib32 CFLAGS=-m32 CXXFLAGS=-m32 \ LDFLAGS='-L/usr/local/lib32 -L/usr/lib32' \ --disable-bin-lttng --disable-bin-lttng-crash \ --disable-bin-lttng-relayd --disable-bin-lttng-sessiond && make && cd src/bin/lttng-consumerd && sudo make install && sudo ldconfig -
From your distribution or from source, install the 64-bit versions of LTTng-UST and Userspace RCU.
-
Download, build, and install the 64-bit version of the latest LTTng-tools 2.10:
$
cd $(mktemp -d) && wget http://lttng.org/files/lttng-tools/lttng-tools-latest-2.10.tar.bz2 && tar -xf lttng-tools-latest-2.10.tar.bz2 && cd lttng-tools-2.10.* && ./configure --with-consumerd32-libdir=/usr/local/lib32 \ --with-consumerd32-bin=/usr/local/lib32/lttng/libexec/lttng-consumerd && make && sudo make install && sudo ldconfig -
Pass the following options to gcc(1), g++(1), or clang(1) when linking your 32-bit application:
-m32 -L/usr/lib32 -L/usr/local/lib32 \ -Wl,-rpath,/usr/lib32,-rpath,/usr/local/lib32
For example, let’s rebuild the quick start example in Trace a user application as an instrumented 32-bit application:
$ $ $
gcc -m32 -c -I. hello-tp.c gcc -m32 -c hello.c gcc -m32 -o hello hello.o hello-tp.o \ -L/usr/lib32 -L/usr/local/lib32 \ -Wl,-rpath,/usr/lib32,-rpath,/usr/local/lib32 \ -llttng-ust -ldl
No special action is required to execute the 32-bit application and to trace it: use the command-line lttng(1) tool as usual.
Use tracef()
Since 2.5
tracef(3) is a small LTTng-UST API designed for quick, printf(3)-like instrumentation without the burden of creating and building a tracepoint provider package.
To use tracef() in your application:
-
In the C or C++ source files where you need to use
tracef(), include<lttng/tracef.h>:#include <lttng/tracef.h>
-
In the application’s source code, use
tracef()like you would use printf(3):/* ... */ tracef("my message: %d (%s)", my_integer, my_string); /* ... */
-
Link your application with
liblttng-ust:$
gcc -o app app.c -llttng-ust
To trace the events that tracef() calls emit:
-
Create an event rule which matches the
lttng_ust_tracef:*event name:$
lttng enable-event --userspace 'lttng_ust_tracef:*'
Limitations of tracef()
Important:The tracef() utility function was developed to make user space tracing
super simple, albeit with notable disadvantages compared to
user-defined tracepoints:
-
All the emitted events have the same tracepoint provider and tracepoint names, respectively
lttng_ust_tracefandevent. -
There is no static type checking.
-
The only event record field you actually get, named
msg, is a string potentially containing the values you passed totracef()using your own format string. This also means that you cannot filter events with a custom expression at run time because there are no isolated fields. -
Since
tracef()uses the C standard library’s vasprintf(3) function behind the scenes to format the strings at run time, its expected performance is lower than with user-defined tracepoints, which do not require a conversion to a string.
Taking this into consideration, tracef() is useful for some quick
prototyping and debugging, but you should not consider it for any
permanent and serious applicative instrumentation.
Use tracelog()
Since 2.7
The tracelog(3) API is very similar to tracef(), with
the difference that it accepts an additional log level parameter.
The goal of tracelog() is to ease the migration from logging to
tracing.
To use tracelog() in your application:
-
In the C or C++ source files where you need to use
tracelog(), include<lttng/tracelog.h>:#include <lttng/tracelog.h>
-
In the application’s source code, use
tracelog()like you would use printf(3), except for the first parameter which is the log level:/* ... */ tracelog(TRACE_WARNING, "my message: %d (%s)", my_integer, my_string); /* ... */
See lttng-ust(3) for a list of available log level names.
-
Link your application with
liblttng-ust:$
gcc -o app app.c -llttng-ust
To trace the events that tracelog() calls emit with a log level
as severe as a specific log level:
-
Create an event rule which matches the
lttng_ust_tracelog:*event name and a minimum level of severity:$
lttng enable-event --userspace 'lttng_ust_tracelog:*' --loglevel=TRACE_WARNING
To trace the events that tracelog() calls emit with a
specific log level:
-
Create an event rule which matches the
lttng_ust_tracelog:*event name and a specific log level:$
lttng enable-event --userspace 'lttng_ust_tracelog:*' --loglevel-only=TRACE_INFO
Prebuilt user space tracing helpers
The LTTng-UST package provides a few helpers in the form of preloadable shared objects which automatically instrument system functions and calls.
The helper shared objects are normally found in /usr/lib. If you
built LTTng-UST from source, they are probably
located in /usr/local/lib.
The installed user space tracing helpers in LTTng-UST 2.10 are:
-
liblttng-ust-libc-wrapper.so -
liblttng-ust-pthread-wrapper.so -
C standard library memory and POSIX threads function tracing.
-
liblttng-ust-cyg-profile.so -
liblttng-ust-cyg-profile-fast.so -
liblttng-ust-dl.so
To use a user space tracing helper with any user application:
-
Preload the helper shared object when you start the application:
$
LD_PRELOAD=liblttng-ust-libc-wrapper.so my-app
You can preload more than one helper:
$
LD_PRELOAD=liblttng-ust-libc-wrapper.so:liblttng-ust-dl.so my-app
Instrument C standard library memory and POSIX threads functions
Since 2.3
The liblttng-ust-libc-wrapper.so and
liblttng-ust-pthread-wrapper.so helpers
add instrumentation to some C standard library and POSIX
threads functions.
Functions instrumented by preloading liblttng-ust-libc-wrapper.so.
| TP provider name | TP name | Instrumented function |
|---|---|---|
|
| |
| ||
| ||
| ||
| ||
|
Functions instrumented by preloading liblttng-ust-pthread-wrapper.so.
| TP provider name | TP name | Instrumented function |
|---|---|---|
|
| pthread_mutex_lock(3p) (request time) |
| pthread_mutex_lock(3p) (acquire time) | |
| ||
|
When you preload the shared object, it replaces the functions listed in the previous tables by wrappers which contain tracepoints and call the replaced functions.
Instrument function entry and exit
The liblttng-ust-cyg-profile*.so helpers can add instrumentation
to the entry and exit points of functions.
gcc(1) and clang(1) have an option named
-finstrument-functions
which generates instrumentation calls for entry and exit to functions.
The LTTng-UST function tracing helpers,
liblttng-ust-cyg-profile.so and
liblttng-ust-cyg-profile-fast.so, take advantage of this feature
to add tracepoints to the two generated functions (which contain
cyg_profile in their names, hence the helper’s name).
To use the LTTng-UST function tracing helper, the source files to
instrument must be built using the -finstrument-functions compiler
flag.
There are two versions of the LTTng-UST function tracing helper:
-
liblttng-ust-cyg-profile-fast.sois a lightweight variant that you should only use when it can be guaranteed that the complete event stream is recorded without any lost event record. Any kind of duplicate information is left out.Assuming no event record is lost, having only the function addresses on entry is enough to create a call graph, since an event record always contains the ID of the CPU that generated it.
You can use a tool like addr2line(1) to convert function addresses back to source file names and line numbers.
-
liblttng-ust-cyg-profile.sois a more robust variant which also works in use cases where event records might get discarded or not recorded from application startup. In these cases, the trace analyzer needs more information to be able to reconstruct the program flow.
See lttng-ust-cyg-profile(3) to learn more about the instrumentation points of this helper.
All the tracepoints that this helper provides have the
log level TRACE_DEBUG_FUNCTION (see lttng-ust(3)).
Tip:It’s sometimes a good idea to limit the number of source files that
you compile with the -finstrument-functions option to prevent LTTng
from writing an excessive amount of trace data at run time. When using
gcc(1), you can use the
-finstrument-functions-exclude-function-list option to avoid
instrument entries and exits of specific function names.
Instrument the dynamic linker
Since 2.4
The liblttng-ust-dl.so helper adds instrumentation to the
dlopen(3) and dlclose(3) function calls.
See lttng-ust-dl(3) to learn more about the instrumentation points of this helper.
User space Java agent
Since 2.4
You can instrument any Java application which uses one of the following logging frameworks:
-
The
java.util.logging(JUL) core logging facilities. -
Apache log4j 1.2, since LTTng 2.6. Note that Apache Log4j 2 is not supported.
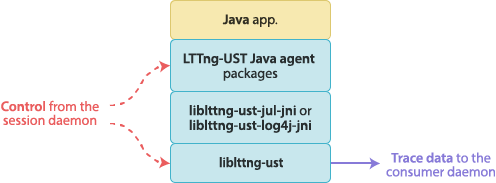
Note that the methods described below are new in LTTng 2.8. Previous LTTng versions use another technique.
Note:We use OpenJDK 8 for development and continuous integration, thus this version is directly supported. However, the LTTng-UST Java agent is also tested with OpenJDK 7.
Use the LTTng-UST Java agent for java.util.logging
Since 2.8
To use the LTTng-UST Java agent in a Java application which uses
java.util.logging (JUL):
-
In the Java application’s source code, import the LTTng-UST log handler package for
java.util.logging:import org.lttng.ust.agent.jul.LttngLogHandler;
-
Create an LTTng-UST JUL log handler:
Handler lttngUstLogHandler = new LttngLogHandler();
-
Add this handler to the JUL loggers which should emit LTTng events:
Logger myLogger = Logger.getLogger("some-logger"); myLogger.addHandler(lttngUstLogHandler);
-
Use
java.util.logginglog statements and configuration as usual. The loggers with an attached LTTng-UST log handler can emit LTTng events. -
Before exiting the application, remove the LTTng-UST log handler from the loggers attached to it and call its
close()method:myLogger.removeHandler(lttngUstLogHandler); lttngUstLogHandler.close();
This is not strictly necessary, but it is recommended for a clean disposal of the handler’s resources.
-
Include the LTTng-UST Java agent’s common and JUL-specific JAR files,
lttng-ust-agent-common.jarandlttng-ust-agent-jul.jar, in the class path when you build the Java application.The JAR files are typically located in
/usr/share/java.Important:The LTTng-UST Java agent must be installed for the logging framework your application uses.
Example:Use the LTTng-UST Java agent for java.util.logging.
Test.java
import java.io.IOException; import java.util.logging.Handler; import java.util.logging.Logger; import org.lttng.ust.agent.jul.LttngLogHandler; public class Test { private static final int answer = 42; public static void main(String[] argv) throws Exception { // Create a logger Logger logger = Logger.getLogger("jello"); // Create an LTTng-UST log handler Handler lttngUstLogHandler = new LttngLogHandler(); // Add the LTTng-UST log handler to our logger logger.addHandler(lttngUstLogHandler); // Log at will! logger.info("some info"); logger.warning("some warning"); Thread.sleep(500); logger.finer("finer information; the answer is " + answer); Thread.sleep(123); logger.severe("error!"); // Not mandatory, but cleaner logger.removeHandler(lttngUstLogHandler); lttngUstLogHandler.close(); } }
Build this example:
$
javac -cp /usr/share/java/jarpath/lttng-ust-agent-common.jar:/usr/share/java/jarpath/lttng-ust-agent-jul.jar Test.java
Create a tracing session,
create an event rule matching the
jello JUL logger, and start tracing:
$ $ $
lttng create lttng enable-event --jul jello lttng start
Run the compiled class:
$
java -cp /usr/share/java/jarpath/lttng-ust-agent-common.jar:/usr/share/java/jarpath/lttng-ust-agent-jul.jar:. Test
Stop tracing and inspect the recorded events:
$ $
lttng stop lttng view
In the resulting trace, an event record generated by a Java
application using java.util.logging is named lttng_jul:event and
has the following fields:
-
msg -
Log record’s message.
-
logger_name -
Logger name.
-
class_name -
Name of the class in which the log statement was executed.
-
method_name -
Name of the method in which the log statement was executed.
-
long_millis -
Logging time (timestamp in milliseconds).
-
int_loglevel -
Log level integer value.
-
int_threadid -
ID of the thread in which the log statement was executed.
You can use the --loglevel or
--loglevel-only option of the
lttng-enable-event(1) command to target a range of JUL log levels
or a specific JUL log level.
Use the LTTng-UST Java agent for Apache log4j
Since 2.8
To use the LTTng-UST Java agent in a Java application which uses Apache log4j 1.2:
-
In the Java application’s source code, import the LTTng-UST log appender package for Apache log4j:
import org.lttng.ust.agent.log4j.LttngLogAppender;
-
Create an LTTng-UST log4j log appender:
Appender lttngUstLogAppender = new LttngLogAppender();
-
Add this appender to the log4j loggers which should emit LTTng events:
Logger myLogger = Logger.getLogger("some-logger"); myLogger.addAppender(lttngUstLogAppender);
-
Use Apache log4j log statements and configuration as usual. The loggers with an attached LTTng-UST log appender can emit LTTng events.
-
Before exiting the application, remove the LTTng-UST log appender from the loggers attached to it and call its
close()method:myLogger.removeAppender(lttngUstLogAppender); lttngUstLogAppender.close();
This is not strictly necessary, but it is recommended for a clean disposal of the appender’s resources.
-
Include the LTTng-UST Java agent’s common and log4j-specific JAR files,
lttng-ust-agent-common.jarandlttng-ust-agent-log4j.jar, in the class path when you build the Java application.The JAR files are typically located in
/usr/share/java.Important:The LTTng-UST Java agent must be installed for the logging framework your application uses.
Example:Use the LTTng-UST Java agent for Apache log4j.
Test.java
import org.apache.log4j.Appender; import org.apache.log4j.Logger; import org.lttng.ust.agent.log4j.LttngLogAppender; public class Test { private static final int answer = 42; public static void main(String[] argv) throws Exception { // Create a logger Logger logger = Logger.getLogger("jello"); // Create an LTTng-UST log appender Appender lttngUstLogAppender = new LttngLogAppender(); // Add the LTTng-UST log appender to our logger logger.addAppender(lttngUstLogAppender); // Log at will! logger.info("some info"); logger.warn("some warning"); Thread.sleep(500); logger.debug("debug information; the answer is " + answer); Thread.sleep(123); logger.fatal("error!"); // Not mandatory, but cleaner logger.removeAppender(lttngUstLogAppender); lttngUstLogAppender.close(); } }
Build this example ($LOG4JPATH is the path to the Apache log4j JAR
file):
$
javac -cp /usr/share/java/jarpath/lttng-ust-agent-common.jar:/usr/share/java/jarpath/lttng-ust-agent-log4j.jar:$LOG4JPATH Test.java
Create a tracing session,
create an event rule matching the
jello log4j logger, and start tracing:
$ $ $
lttng create lttng enable-event --log4j jello lttng start
Run the compiled class:
$
java -cp /usr/share/java/jarpath/lttng-ust-agent-common.jar:/usr/share/java/jarpath/lttng-ust-agent-log4j.jar:$LOG4JPATH:. Test
Stop tracing and inspect the recorded events:
$ $
lttng stop lttng view
In the resulting trace, an event record generated by a Java
application using log4j is named lttng_log4j:event and
has the following fields:
-
msg -
Log record’s message.
-
logger_name -
Logger name.
-
class_name -
Name of the class in which the log statement was executed.
-
method_name -
Name of the method in which the log statement was executed.
-
filename -
Name of the file in which the executed log statement is located.
-
line_number -
Line number at which the log statement was executed.
-
timestamp -
Logging timestamp.
-
int_loglevel -
Log level integer value.
-
thread_name -
Name of the Java thread in which the log statement was executed.
You can use the --loglevel or
--loglevel-only option of the
lttng-enable-event(1) command to target a range of Apache log4j log levels
or a specific log4j log level.
Provide application-specific context fields in a Java application
Since 2.8
A Java application-specific context field is a piece of state provided by the application which you can add, using the lttng-add-context(1) command, to each event record produced by the log statements of this application.
For example, a given object might have a current request ID variable. You can create a context information retriever for this object and assign a name to this current request ID. You can then, using the lttng-add-context(1) command, add this context field by name to the JUL or log4j channel.
To provide application-specific context fields in a Java application:
-
In the Java application’s source code, import the LTTng-UST Java agent context classes and interfaces:
import org.lttng.ust.agent.context.ContextInfoManager; import org.lttng.ust.agent.context.IContextInfoRetriever;
-
Create a context information retriever class, that is, a class which implements the
IContextInfoRetrieverinterface:class MyContextInfoRetriever implements IContextInfoRetriever { @Override public Object retrieveContextInfo(String key) { if (key.equals("intCtx")) { return (short) 17; } else if (key.equals("strContext")) { return "context value!"; } else { return null; } } }
This
retrieveContextInfo()method is the only member of theIContextInfoRetrieverinterface. Its role is to return the current value of a state by name to create a context field. The names of the context fields and which state variables they return depends on your specific scenario.All primitive types and objects are supported as context fields. When
retrieveContextInfo()returns an object, the context field serializer calls itstoString()method to add a string field to event records. The method can also returnnull, which means that no context field is available for the required name. -
Register an instance of your context information retriever class to the context information manager singleton:
IContextInfoRetriever cir = new MyContextInfoRetriever(); ContextInfoManager cim = ContextInfoManager.getInstance(); cim.registerContextInfoRetriever("retrieverName", cir);
-
Before exiting the application, remove your context information retriever from the context information manager singleton:
ContextInfoManager cim = ContextInfoManager.getInstance(); cim.unregisterContextInfoRetriever("retrieverName");
This is not strictly necessary, but it is recommended for a clean disposal of some manager’s resources.
-
Build your Java application with LTTng-UST Java agent support as usual, following the procedure for either the JUL or Apache log4j framework.
Example:Provide application-specific context fields in a Java application.
Test.java
import java.util.logging.Handler; import java.util.logging.Logger; import org.lttng.ust.agent.jul.LttngLogHandler; import org.lttng.ust.agent.context.ContextInfoManager; import org.lttng.ust.agent.context.IContextInfoRetriever; public class Test { // Our context information retriever class private static class MyContextInfoRetriever implements IContextInfoRetriever { @Override public Object retrieveContextInfo(String key) { if (key.equals("intCtx")) { return (short) 17; } else if (key.equals("strContext")) { return "context value!"; } else { return null; } } } private static final int answer = 42; public static void main(String args[]) throws Exception { // Get the context information manager instance ContextInfoManager cim = ContextInfoManager.getInstance(); // Create and register our context information retriever IContextInfoRetriever cir = new MyContextInfoRetriever(); cim.registerContextInfoRetriever("myRetriever", cir); // Create a logger Logger logger = Logger.getLogger("jello"); // Create an LTTng-UST log handler Handler lttngUstLogHandler = new LttngLogHandler(); // Add the LTTng-UST log handler to our logger logger.addHandler(lttngUstLogHandler); // Log at will! logger.info("some info"); logger.warning("some warning"); Thread.sleep(500); logger.finer("finer information; the answer is " + answer); Thread.sleep(123); logger.severe("error!"); // Not mandatory, but cleaner logger.removeHandler(lttngUstLogHandler); lttngUstLogHandler.close(); cim.unregisterContextInfoRetriever("myRetriever"); } }
Build this example:
$
javac -cp /usr/share/java/jarpath/lttng-ust-agent-common.jar:/usr/share/java/jarpath/lttng-ust-agent-jul.jar Test.java
Create a tracing session
and create an event rule matching the
jello JUL logger:
$ $
lttng create lttng enable-event --jul jello
Add the application-specific context fields to the JUL channel:
$ $
lttng add-context --jul --type='$app.myRetriever:intCtx' lttng add-context --jul --type='$app.myRetriever:strContext'
$
lttng start
Run the compiled class:
$
java -cp /usr/share/java/jarpath/lttng-ust-agent-common.jar:/usr/share/java/jarpath/lttng-ust-agent-jul.jar:. Test
Stop tracing and inspect the recorded events:
$ $
lttng stop lttng view
User space Python agent
Since 2.7
You can instrument a Python 2 or Python 3 application which uses the
standard logging
package.
Each log statement emits an LTTng event once the application module imports the LTTng-UST Python agent package.
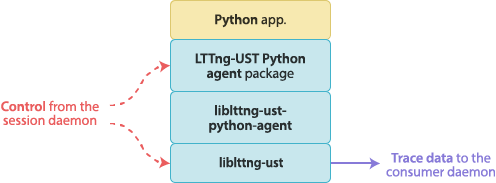
To use the LTTng-UST Python agent:
-
In the Python application’s source code, import the LTTng-UST Python agent:
import lttngust
The LTTng-UST Python agent automatically adds its logging handler to the root logger at import time.
Any log statement that the application executes before this import does not emit an LTTng event.
Important:The LTTng-UST Python agent must be installed.
-
Use log statements and logging configuration as usual. Since the LTTng-UST Python agent adds a handler to the root logger, you can trace any log statement from any logger.
Example:Use the LTTng-UST Python agent.
test.py
import lttngust import logging import time def example(): logging.basicConfig() logger = logging.getLogger('my-logger') while True: logger.debug('debug message') logger.info('info message') logger.warn('warn message') logger.error('error message') logger.critical('critical message') time.sleep(1) if __name__ == '__main__': example()
Note:logging.basicConfig(), which adds to the root logger a basic
logging handler which prints to the standard error stream, is not
strictly required for LTTng-UST tracing to work, but in versions of
Python preceding 3.2, you could see a warning message which indicates
that no handler exists for the logger my-logger.
Create a tracing session,
create an event rule matching the
my-logger Python logger, and start tracing:
$ $ $
lttng create lttng enable-event --python my-logger lttng start
Run the Python script:
$
python test.py
Stop tracing and inspect the recorded events:
$ $
lttng stop lttng view
In the resulting trace, an event record generated by a Python
application is named lttng_python:event and has the following fields:
-
asctime -
Logging time (string).
-
msg -
Log record’s message.
-
logger_name -
Logger name.
-
funcName -
Name of the function in which the log statement was executed.
-
lineno -
Line number at which the log statement was executed.
-
int_loglevel -
Log level integer value.
-
thread -
ID of the Python thread in which the log statement was executed.
-
threadName -
Name of the Python thread in which the log statement was executed.
You can use the --loglevel or
--loglevel-only option of the
lttng-enable-event(1) command to target a range of Python log levels
or a specific Python log level.
When an application imports the LTTng-UST Python agent, the agent tries
to register to a session daemon. Note that you must
start the session daemon before you run the Python
application. If a session daemon is found, the agent tries to register
to it during 5 seconds, after which the application continues
without LTTng tracing support. You can override this timeout value with
the LTTNG_UST_PYTHON_REGISTER_TIMEOUT environment variable
(milliseconds).
If the session daemon stops while a Python application with an imported
LTTng-UST Python agent runs, the agent retries to connect and to
register to a session daemon every 3 seconds. You can override this
delay with the LTTNG_UST_PYTHON_REGISTER_RETRY_DELAY environment
variable.
LTTng logger
Since 2.5
The lttng-tracer Linux kernel module, part of
LTTng-modules, creates the special LTTng logger file
/proc/lttng-logger when it’s loaded. Any application can write
text data to this file to emit an LTTng event.

The LTTng logger is the quickest method—not the most efficient, however—to add instrumentation to an application. It is designed mostly to instrument shell scripts:
$
echo "Some message, some $variable" > /proc/lttng-logger
Any event that the LTTng logger emits is named lttng_logger and
belongs to the Linux kernel tracing domain. However, unlike
other instrumentation points in the kernel tracing domain, any Unix
user can create an event rule which
matches its event name, not only the root user or users in the
tracing group.
To use the LTTng logger:
-
From any application, write text data to the
/proc/lttng-loggerfile.
The msg field of lttng_logger event records contains the
recorded message.
Note:The maximum message length of an LTTng logger event is 1024 bytes. Writing more than this makes the LTTng logger emit more than one event to contain the remaining data.
You should not use the LTTng logger to trace a user application which can be instrumented in a more efficient way, namely:
Example:Use the LTTng logger.
test.bash
echo 'Hello, World!' > /proc/lttng-logger sleep 2 df --human-readable --print-type / > /proc/lttng-logger
Create a tracing session,
create an event rule matching the
lttng_logger Linux kernel tracepoint, and
start tracing:
$ $ $
lttng create lttng enable-event --kernel lttng_logger lttng start
Run the Bash script:
$
bash test.bash
Stop tracing and inspect the recorded events:
$ $
lttng stop lttng view
LTTng kernel tracepoints
Note:This section shows how to add instrumentation points to the Linux kernel. The kernel’s subsystems are already thoroughly instrumented at strategic places for LTTng when you install the LTTng-modules package.
Add an LTTng layer to an existing ftrace tracepoint
This section shows how to add an LTTng layer to existing ftrace
instrumentation using the TRACE_EVENT() API.
This section does not document the TRACE_EVENT() macro. You can
read the following articles to learn more about this API:
The following procedure assumes that your ftrace tracepoints are
correctly defined in their own header and that they are created in
one source file using the CREATE_TRACE_POINTS definition.
To add an LTTng layer over an existing ftrace tracepoint:
-
Make sure the following kernel configuration options are enabled:
-
CONFIG_MODULES -
CONFIG_KALLSYMS -
CONFIG_HIGH_RES_TIMERS -
CONFIG_TRACEPOINTS
-
-
Build the Linux source tree with your custom ftrace tracepoints.
-
Boot the resulting Linux image on your target system.
Confirm that the tracepoints exist by looking for their names in the
/sys/kernel/debug/tracing/events/subsysdirectory, wheresubsysis your subsystem’s name. -
Get a copy of the latest LTTng-modules 2.10:
$
cd $(mktemp -d) && wget http://lttng.org/files/lttng-modules/lttng-modules-latest-2.10.tar.bz2 && tar -xf lttng-modules-latest-2.10.tar.bz2 && cd lttng-modules-2.10.*
-
In
instrumentation/events/lttng-module, relative to the root of the LTTng-modules source tree, create a header file namedsubsys.hfor your custom subsystemsubsysand write your LTTng-modules tracepoint definitions using the LTTng-modules macros in it.Start with this template:
instrumentation/events/lttng-module/my_subsys.h#undef TRACE_SYSTEM #define TRACE_SYSTEM my_subsys #if !defined(_LTTNG_MY_SUBSYS_H) || defined(TRACE_HEADER_MULTI_READ) #define _LTTNG_MY_SUBSYS_H #include "../../../probes/lttng-tracepoint-event.h" #include <linux/tracepoint.h> LTTNG_TRACEPOINT_EVENT( /* * Format is identical to TRACE_EVENT()'s version for the three * following macro parameters: */ my_subsys_my_event, TP_PROTO(int my_int, const char *my_string), TP_ARGS(my_int, my_string), /* LTTng-modules specific macros */ TP_FIELDS( ctf_integer(int, my_int_field, my_int) ctf_string(my_bar_field, my_bar) ) ) #endif /* !defined(_LTTNG_MY_SUBSYS_H) || defined(TRACE_HEADER_MULTI_READ) */ #include "../../../probes/define_trace.h"
The entries in the
TP_FIELDS()section are the list of fields for the LTTng tracepoint. This is similar to theTP_STRUCT__entry()part of ftrace’sTRACE_EVENT()macro.See Tracepoint fields macros for a complete description of the available
ctf_*()macros. -
Create the LTTng-modules probe’s kernel module C source file,
probes/lttng-probe-subsys.c, wheresubsysis your subsystem name:probes/lttng-probe-my-subsys.c#include <linux/module.h> #include "../lttng-tracer.h" /* * Build-time verification of mismatch between mainline * TRACE_EVENT() arguments and the LTTng-modules adaptation * layer LTTNG_TRACEPOINT_EVENT() arguments. */ #include <trace/events/my_subsys.h> /* Create LTTng tracepoint probes */ #define LTTNG_PACKAGE_BUILD #define CREATE_TRACE_POINTS #define TRACE_INCLUDE_PATH ../instrumentation/events/lttng-module #include "../instrumentation/events/lttng-module/my_subsys.h" MODULE_LICENSE("GPL and additional rights"); MODULE_AUTHOR("Your name <your-email>"); MODULE_DESCRIPTION("LTTng my_subsys probes"); MODULE_VERSION(__stringify(LTTNG_MODULES_MAJOR_VERSION) "." __stringify(LTTNG_MODULES_MINOR_VERSION) "." __stringify(LTTNG_MODULES_PATCHLEVEL_VERSION) LTTNG_MODULES_EXTRAVERSION);
-
Edit
probes/KBuildand add your new kernel module object next to the existing ones:probes/KBuild# ... obj-m += lttng-probe-module.o obj-m += lttng-probe-power.o obj-m += lttng-probe-my-subsys.o # ...
-
Build and install the LTTng kernel modules:
$ #
make KERNELDIR=/path/to/linux make modules_install && depmod -a
Replace
/path/to/linuxwith the path to the Linux source tree where you defined and used tracepoints with ftrace’sTRACE_EVENT()macro.
Note that you can also use the
LTTNG_TRACEPOINT_EVENT_CODE() macro
instead of LTTNG_TRACEPOINT_EVENT() to use custom local variables and
C code that need to be executed before the event fields are recorded.
The best way to learn how to use the previous LTTng-modules macros is to
inspect the existing LTTng-modules tracepoint definitions in the
instrumentation/events/lttng-module header files. Compare them
with the Linux kernel mainline versions in the
include/trace/events directory of the Linux source tree.
Use custom C code to access the data for tracepoint fields
Since 2.7
Although we recommended to always use the
LTTNG_TRACEPOINT_EVENT() macro to describe
the arguments and fields of an LTTng-modules tracepoint when possible,
sometimes you need a more complex process to access the data that the
tracer records as event record fields. In other words, you need local
variables and multiple C statements instead of simple
argument-based expressions that you pass to the
ctf_*() macros of TP_FIELDS().
You can use the LTTNG_TRACEPOINT_EVENT_CODE() macro instead of
LTTNG_TRACEPOINT_EVENT() to declare custom local variables and define
a block of C code to be executed before LTTng records the fields.
The structure of this macro is:
LTTNG_TRACEPOINT_EVENT_CODE() macro syntax.
LTTNG_TRACEPOINT_EVENT_CODE( /* * Format identical to the LTTNG_TRACEPOINT_EVENT() * version for the following three macro parameters: */ my_subsys_my_event, TP_PROTO(int my_int, const char *my_string), TP_ARGS(my_int, my_string), /* Declarations of custom local variables */ TP_locvar( int a = 0; unsigned long b = 0; const char *name = "(undefined)"; struct my_struct *my_struct; ), /* * Custom code which uses both tracepoint arguments * (in TP_ARGS()) and local variables (in TP_locvar()). * * Local variables are actually members of a structure pointed * to by the special variable tp_locvar. */ TP_code( if (my_int) { tp_locvar->a = my_int + 17; tp_locvar->my_struct = get_my_struct_at(tp_locvar->a); tp_locvar->b = my_struct_compute_b(tp_locvar->my_struct); tp_locvar->name = my_struct_get_name(tp_locvar->my_struct); put_my_struct(tp_locvar->my_struct); if (tp_locvar->b) { tp_locvar->a = 1; } } ), /* * Format identical to the LTTNG_TRACEPOINT_EVENT() * version for this, except that tp_locvar members can be * used in the argument expression parameters of * the ctf_*() macros. */ TP_FIELDS( ctf_integer(unsigned long, my_struct_b, tp_locvar->b) ctf_integer(int, my_struct_a, tp_locvar->a) ctf_string(my_string_field, my_string) ctf_string(my_struct_name, tp_locvar->name) ) )
Important:The C code defined in TP_code() must not have any side
effects when executed. In particular, the code must not allocate
memory or get resources without deallocating this memory or putting
those resources afterwards.
Load and unload a custom probe kernel module
You must load a created LTTng-modules probe kernel module in the kernel before it can emit LTTng events.
To load the default probe kernel modules and a custom probe kernel module:
-
Use the
--extra-kmod-probesoption to give extra probe modules to load when starting a root session daemon:Example:Load the
my_subsys,usb, and the default probe modules.#
lttng-sessiond --extra-kmod-probes=my_subsys,usb
You only need to pass the subsystem name, not the whole kernel module name.
To load only a given custom probe kernel module:
-
Use the
--kmod-probesoption to give the probe modules to load when starting a root session daemon:Example:Load only the
my_subsysandusbprobe modules.#
lttng-sessiond --kmod-probes=my_subsys,usb
To confirm that a probe module is loaded:
-
Use lsmod(8):
$
lsmod | grep lttng_probe_usb
To unload the loaded probe modules:
-
Kill the session daemon with
SIGTERM:#
pkill lttng-sessiond
You can also use modprobe(8)'s
--removeoption if the session daemon terminates abnormally.
Tracing control
Once an application or a Linux kernel is instrumented for LTTng tracing, you can trace it.
This section is divided in topics on how to use the various
components of LTTng, in particular the lttng command-line tool, to control the LTTng daemons and tracers.
Note:In the following subsections, we refer to an lttng(1) command
using its man page name. For example, instead of Run the create
command to…, we use Run the lttng-create(1) command to….
Start a session daemon
In some situations, you need to run a session daemon (lttng-sessiond(8)) before you can use the lttng(1) command-line tool.
You will see the following error when you run a command while no session daemon is running:
Error: No session daemon is available
The only command that automatically runs a session daemon is lttng-create(1), which you use to create a tracing session. While this is most of the time the first operation that you do, sometimes it’s not. Some examples are:
Each Unix user must have its own running session
daemon to trace user applications. The session daemon that the root user
starts is the only one allowed to control the LTTng kernel tracer. Users
that are part of the tracing group can control the root session
daemon. The default tracing group name is tracing; you can set it to
something else with the --group option when you
start the root session daemon.
To start a user session daemon:
-
Run lttng-sessiond(8):
$
lttng-sessiond --daemonize
To start the root session daemon:
-
Run lttng-sessiond(8) as the root user:
#
lttng-sessiond --daemonize
In both cases, remove the --daemonize option to
start the session daemon in foreground.
To stop a session daemon, use kill(1) on its process ID (standard
TERM signal).
Note that some Linux distributions could manage the LTTng session daemon as a service. In this case, you should use the service manager to start, restart, and stop session daemons.
Create and destroy a tracing session
Almost all the LTTng control operations happen in the scope of a tracing session, which is the dialogue between the session daemon and you.
To create a tracing session with a generated name:
-
Use the lttng-create(1) command:
$
lttng create
The created tracing session’s name is auto followed by the
creation date.
To create a tracing session with a specific name:
-
Use the optional argument of the lttng-create(1) command:
$
lttng create my-session
Replace
my-sessionwith the specific tracing session name.
LTTng appends the creation date to the created tracing session’s name.
LTTng writes the traces of a tracing session in
$LTTNG_HOME/lttng-trace/name by default, where name is the
name of the tracing session. Note that the LTTNG_HOME environment
variable defaults to $HOME if not set.
To output LTTng traces to a non-default location:
-
Use the
--outputoption of the lttng-create(1) command:$
lttng create my-session --output=/tmp/some-directory
You may create as many tracing sessions as you wish.
To list all the existing tracing sessions for your Unix user:
-
Use the lttng-list(1) command:
$
lttng list
When you create a tracing session, it is set as the current tracing session. The following lttng(1) commands operate on the current tracing session when you don’t specify one:
-
add-context -
destroy -
disable-channel -
disable-event -
enable-channel -
enable-event -
load -
regenerate -
save -
snapshot -
start -
stop -
track -
untrack -
view
To change the current tracing session:
-
Use the lttng-set-session(1) command:
$
lttng set-session new-session
Replace
new-sessionby the name of the new current tracing session.
When you are done tracing in a given tracing session, you can destroy it. This operation frees the resources taken by the tracing session to destroy; it does not destroy the trace data that LTTng wrote for this tracing session.
To destroy the current tracing session:
-
Use the lttng-destroy(1) command:
$
lttng destroy
The lttng-destroy(1) command also runs the lttng-stop(1) command implicitly (see Start and stop a tracing session). You need to stop tracing to make LTTng flush the remaining trace data and make the trace readable.
List the available instrumentation points
The session daemon can query the running instrumented user applications and the Linux kernel to get a list of available instrumentation points. For the Linux kernel tracing domain, they are tracepoints and system calls. For the user space tracing domain, they are tracepoints. For the other tracing domains, they are logger names.
To list the available instrumentation points:
-
Use the lttng-list(1) command with the requested tracing domain’s option amongst:
-
--kernel: Linux kernel tracepoints (your Unix user must be a root user, or it must be a member of the tracing group). -
--kernelwith--syscall: Linux kernel system calls (your Unix user must be a root user, or it must be a member of the tracing group). -
--userspace: user space tracepoints. -
--jul:java.util.loggingloggers. -
--log4j: Apache log4j loggers. -
--python: Python loggers.
-
Example:List the available user space tracepoints.
$
lttng list --userspace
Example:List the available Linux kernel system call tracepoints.
$
lttng list --kernel --syscall
Create and enable an event rule
Once you create a tracing session, you can create event rules with the lttng-enable-event(1) command.
You specify each condition with a command-line option. The available condition options are shown in the following table.
Condition command-line options for the lttng-enable-event(1) command.
| Option | Description | Applicable tracing domains |
|---|---|---|
One of:
| Instead of using the default tracepoint instrumentation type, use:
| Linux kernel. |
First positional argument. | Tracepoint or system call name. In the case of a Linux KProbe or function, this is a custom name given to the event rule. With the JUL, log4j, and Python domains, this is a logger name. With a tracepoint, logger, or system call name, you can use the special
| All. |
One of:
|
See lttng-enable-event(1) for the list of available logging level names. | User space, JUL, log4j, and Python. |
| When you use a | User space, JUL, log4j, and Python. |
| Match only events which satisfy the expression See lttng-enable-event(1) to learn more about the syntax of a filter expression. | All. |
You attach an event rule to a channel on creation. If you do
not specify the channel with the --channel
option, and if the event rule to create is the first in its
tracing domain for a given tracing session, then LTTng
creates a default channel for you. This default channel is reused in
subsequent invocations of the lttng-enable-event(1) command for the
same tracing domain.
An event rule is always enabled at creation time.
The following examples show how you can combine the previous command-line options to create simple to more complex event rules.
Example:Create an event rule targetting a Linux kernel tracepoint (default channel).
$
lttng enable-event --kernel sched_switch
Example:Create an event rule matching four Linux kernel system calls (default channel).
$
lttng enable-event --kernel --syscall open,write,read,close
Example:Create event rules matching tracepoints with filter expressions (default channel).
$
lttng enable-event --kernel sched_switch --filter='prev_comm == "bash"'
$
lttng enable-event --kernel --all \
--filter='$ctx.tid == 1988 || $ctx.tid == 1534'$
lttng enable-event --jul my_logger \
--filter='$app.retriever:cur_msg_id > 3'Important:Make sure to always quote the filter string when you use lttng(1) from a shell.
Example:Create an event rule matching any user space tracepoint of a given tracepoint provider with a log level range (default channel).
$
lttng enable-event --userspace my_app:'*' --loglevel=TRACE_INFO
Important:Make sure to always quote the wildcard character when you use lttng(1) from a shell.
Example:Create an event rule matching multiple Python loggers with a wildcard and with exclusions (default channel).
$
lttng enable-event --python my-app.'*' \
--exclude='my-app.module,my-app.hello'Example:Create an event rule matching any Apache log4j logger with a specific log level (default channel).
$
lttng enable-event --log4j --all --loglevel-only=LOG4J_WARN
Example:Create an event rule attached to a specific channel matching a specific user space tracepoint provider and tracepoint.
$
lttng enable-event --userspace my_app:my_tracepoint --channel=my-channel
The event rules of a given channel form a whitelist: as soon as an
emitted event passes one of them, LTTng can record the event. For
example, an event named my_app:my_tracepoint emitted from a user space
tracepoint with a TRACE_ERROR log level passes both of the following
rules:
$ $
lttng enable-event --userspace my_app:my_tracepoint
lttng enable-event --userspace my_app:my_tracepoint \
--loglevel=TRACE_INFOThe second event rule is redundant: the first one includes the second one.
Disable an event rule
To disable an event rule that you created previously, use the lttng-disable-event(1) command. This command disables all the event rules (of a given tracing domain and channel) which match an instrumentation point. The other conditions are not supported as of LTTng 2.10.
The LTTng tracer does not record an emitted event which passes a disabled event rule.
Example:Disable an event rule matching a Python logger (default channel).
$
lttng disable-event --python my-logger
Example:Disable an event rule matching all java.util.logging loggers (default channel).
$
lttng disable-event --jul '*'
Example:Disable all the event rules of the default channel.
The --all-events option is not, like the
--all option of lttng-enable-event(1), the
equivalent of the event name * (wildcard): it disables all the event
rules of a given channel.
$
lttng disable-event --jul --all-events
Note:You cannot delete an event rule once you create it.
Get the status of a tracing session
To get the status of the current tracing session, that is, its parameters, its channels, event rules, and their attributes:
-
Use the lttng-status(1) command:
$
lttng status
To get the status of any tracing session:
-
Use the lttng-list(1) command with the tracing session’s name:
$
lttng list my-session
Replace
my-sessionwith the desired tracing session’s name.
Start and stop a tracing session
Once you create a tracing session and create one or more event rules, you can start and stop the tracers for this tracing session.
To start tracing in the current tracing session:
-
Use the lttng-start(1) command:
$
lttng start
LTTng is very flexible: you can launch user applications before or after the you start the tracers. The tracers only record the events if they pass enabled event rules and if they occur while the tracers are started.
To stop tracing in the current tracing session:
-
Use the lttng-stop(1) command:
$
lttng stop
If there were lost event records or lost sub-buffers since the last time you ran lttng-start(1), warnings are printed when you run the lttng-stop(1) command.
Important:You need to stop tracing to make LTTng flush the remaining trace data and make the trace readable. Note that the lttng-destroy(1) command (see Create and destroy a tracing session) also runs the lttng-stop(1) command implicitly.
Create a channel
Once you create a tracing session, you can create a channel with the lttng-enable-channel(1) command.
Note that LTTng automatically creates a default channel when, for a
given tracing domain, no channels exist and you
create the first event rule. This default
channel is named channel0 and its attributes are set to reasonable
values. Therefore, you only need to create a channel when you need
non-default attributes.
You specify each non-default channel attribute with a command-line option when you use the lttng-enable-channel(1) command. The available command-line options are:
Command-line options for the lttng-enable-channel(1) command.
| Option | Description |
|---|---|
| Use the overwrite event loss mode instead of the default discard mode. |
| Use the per-process buffering scheme instead of the default per-user buffering scheme. |
| Allocate sub-buffers of |
| Allocate |
| Set the maximum size of each trace file that this channel writes within
a stream to |
| Limit the number of trace files that this channel creates to
|
| Set the switch timer period
to |
| Set the read timer period
to |
| Set the timeout of user space applications which load LTTng-UST
in blocking mode to
Note that, for this option to have any effect on an instrumented
user space application, you need to run the application with a set
|
| Set the channel’s output type to |
You can only create a channel in the Linux kernel and user space tracing domains: other tracing domains have their own channel created on the fly when creating event rules.
Important:Because of a current LTTng limitation, you must create all channels before you start tracing in a given tracing session, that is, before the first time you run lttng-start(1).
Since LTTng automatically creates a default channel when you use the lttng-enable-event(1) command with a specific tracing domain, you cannot, for example, create a Linux kernel event rule, start tracing, and then create a user space event rule, because no user space channel exists yet and it’s too late to create one.
For this reason, make sure to configure your channels properly before starting the tracers for the first time!
The following examples show how you can combine the previous command-line options to create simple to more complex channels.
Example:Create a Linux kernel channel with default attributes.
$
lttng enable-channel --kernel my-channel
Example:Create a user space channel with 4 sub-buffers or 1 MiB each, per CPU, per instrumented process.
$
lttng enable-channel --userspace --num-subbuf=4 --subbuf-size=1M \
--buffers-pid my-channelExample:Create a default user space channel with an infinite blocking timeout.
Create a tracing-session, create the channel, create an event rule, and start tracing:
$ $ $ $
lttng create lttng enable-channel --userspace --blocking-timeout=inf blocking-channel lttng enable-event --userspace --channel=blocking-channel --all lttng start
Run an application instrumented with LTTng-UST and allow it to block:
$
LTTNG_UST_ALLOW_BLOCKING=1 my-app
Example:Create a Linux kernel channel which rotates 8 trace files of 4 MiB each for each stream
$
lttng enable-channel --kernel --tracefile-count=8 \
--tracefile-size=4194304 my-channelExample:Create a user space channel in overwrite (or flight recorder) mode.
$
lttng enable-channel --userspace --overwrite my-channel
You can create the same event rule in two different channels:
$ $
lttng enable-event --userspace --channel=my-channel app:tp lttng enable-event --userspace --channel=other-channel app:tp
If both channels are enabled, when a tracepoint named app:tp is
reached, LTTng records two events, one for each channel.
Disable a channel
To disable a specific channel that you created previously, use the lttng-disable-channel(1) command.
Example:Disable a specific Linux kernel channel.
$
lttng disable-channel --kernel my-channel
The state of a channel precedes the individual states of event rules attached to it: event rules which belong to a disabled channel, even if they are enabled, are also considered disabled.
Add context fields to a channel
Event record fields in trace files provide important information about events that occured previously, but sometimes some external context may help you solve a problem faster. Examples of context fields are:
-
The process ID, thread ID, process name, and process priority of the thread in which the event occurs.
-
The hostname of the system on which the event occurs.
-
The current values of many possible performance counters using perf, for example:
-
CPU cycles, stalled cycles, idle cycles, and the other cycle types.
-
Cache misses.
-
Branch instructions, misses, and loads.
-
CPU faults.
-
-
Any context defined at the application level (supported for the JUL and log4j tracing domains).
To get the full list of available context fields, see
lttng add-context --list. Some context fields are reserved for a
specific tracing domain (Linux kernel or user space).
You add context fields to channels. All the events that a channel with added context fields records contain those fields.
To add context fields to one or all the channels of a given tracing session:
-
Use the lttng-add-context(1) command.
Example:Add context fields to all the channels of the current tracing session.
The following command line adds the virtual process identifier and the per-thread CPU cycles count fields to all the user space channels of the current tracing session.
$
lttng add-context --userspace --type=vpid --type=perf:thread:cpu-cycles
Example:Add performance counter context fields by raw ID
See lttng-add-context(1) for the exact format of the context field type, which is partly compatible with the format used in perf-record(1).
$ $
lttng add-context --userspace --type=perf:thread:raw:r0110:test lttng add-context --kernel --type=perf:cpu:raw:r0013c:x86unhalted
Example:Add a context field to a specific channel.
The following command line adds the thread identifier context field
to the Linux kernel channel named my-channel in the current
tracing session.
$
lttng add-context --kernel --channel=my-channel --type=tid
Example:Add an application-specific context field to a specific channel.
The following command line adds the cur_msg_id context field of the
retriever context retriever for all the instrumented
Java applications recording event records
in the channel named my-channel:
$
lttng add-context --kernel --channel=my-channel \
--type='$app:retriever:cur_msg_id'Important:Make sure to always quote the $ character when you
use lttng-add-context(1) from a shell.
Note:You cannot remove context fields from a channel once you add it.
Track process IDs
Since 2.7
It’s often useful to allow only specific process IDs (PIDs) to emit events. For example, you may wish to record all the system calls made by a given process (à la strace).
The lttng-track(1) and lttng-untrack(1) commands serve this purpose. Both commands operate on a whitelist of process IDs. You add entries to this whitelist with the lttng-track(1) command and remove entries with the lttng-untrack(1) command. Any process which has one of the PIDs in the whitelist is allowed to emit LTTng events which pass an enabled event rule.
Note:The PID tracker tracks the numeric process IDs. Should a process with a given tracked ID exit and another process be given this ID, then the latter would also be allowed to emit events.
Example:Track and untrack process IDs.
For the sake of the following example, assume the target system has 16 possible PIDs.
When you create a tracing session, the whitelist contains all the possible PIDs:

When the whitelist is full and you use the lttng-track(1) command to specify some PIDs to track, LTTng first clears the whitelist, then it tracks the specific PIDs. After:
$
lttng track --pid=3,4,7,10,13
the whitelist is:

You can add more PIDs to the whitelist afterwards:
$
lttng track --pid=1,15,16
The result is:

The lttng-untrack(1) command removes entries from the PID tracker’s whitelist. Given the previous example, the following command:
$
lttng untrack --pid=3,7,10,13
leads to this whitelist:

LTTng can track all possible PIDs again using the
--all option:
$
lttng track --pid --all
The result is, again:
Example:Track only specific PIDs
A very typical use case with PID tracking is to start with an empty
whitelist, then start the tracers, and
then add PIDs manually while tracers are active. You can accomplish this
by using the --all option of the
lttng-untrack(1) command to clear the whitelist after you
create a tracing session:
$
lttng untrack --pid --all
gives:
If you trace with this whitelist configuration, the tracer records no events for this tracing domain because no processes are tracked. You can use the lttng-track(1) command as usual to track specific PIDs, for example:
$
lttng track --pid=6,11
Result:

Save and load tracing session configurations
Since 2.5
Configuring a tracing session can be long. Some of the tasks involved are:
-
Create channels with specific attributes.
-
Add context fields to specific channels.
-
Create event rules with specific log level and filter conditions.
If you use LTTng to solve real world problems, chances are you have to record events using the same tracing session setup over and over, modifying a few variables each time in your instrumented program or environment. To avoid constant tracing session reconfiguration, the lttng(1) command-line tool can save and load tracing session configurations to/from XML files.
To save a given tracing session configuration:
-
Use the lttng-save(1) command:
$
lttng save my-session
Replace
my-sessionwith the name of the tracing session to save.
LTTng saves tracing session configurations to
$LTTNG_HOME/.lttng/sessions by default. Note that the
LTTNG_HOME environment variable defaults to $HOME if not set. Use
the --output-path option to change this destination
directory.
LTTng saves all configuration parameters, for example:
-
The tracing session name.
-
The trace data output path.
-
The channels with their state and all their attributes.
-
The context fields you added to channels.
-
The event rules with their state, log level and filter conditions.
To load a tracing session:
-
Use the lttng-load(1) command:
$
lttng load my-session
Replace
my-sessionwith the name of the tracing session to load.
When LTTng loads a configuration, it restores your saved tracing session as if you just configured it manually.
See lttng(1) for the complete list of command-line options. You can also save and load all many sessions at a time, and decide in which directory to output the XML files.
Send trace data over the network
LTTng can send the recorded trace data to a remote system over the network instead of writing it to the local file system.
To send the trace data over the network:
-
On the remote system (which can also be the target system), start an LTTng relay daemon (lttng-relayd(8)):
$
lttng-relayd
-
On the target system, create a tracing session configured to send trace data over the network:
$
lttng create my-session --set-url=net://remote-system
Replace
remote-systemby the host name or IP address of the remote system. See lttng-create(1) for the exact URL format. -
On the target system, use the lttng(1) command-line tool as usual. When tracing is active, the target’s consumer daemon sends sub-buffers to the relay daemon running on the remote system instead of flushing them to the local file system. The relay daemon writes the received packets to the local file system.
The relay daemon writes trace files to
$LTTNG_HOME/lttng-traces/hostname/session by default, where
hostname is the host name of the target system and session
is the tracing session name. Note that the LTTNG_HOME environment
variable defaults to $HOME if not set. Use the
--output option of lttng-relayd(8) to write
trace files to another base directory.
View events as LTTng emits them (LTTng live)
Since 2.4
LTTng live is a network protocol implemented by the relay daemon (lttng-relayd(8)) to allow compatible trace viewers to display events as LTTng emits them on the target system while tracing is active.
The relay daemon creates a tee: it forwards the trace data to both the local file system and to connected live viewers:
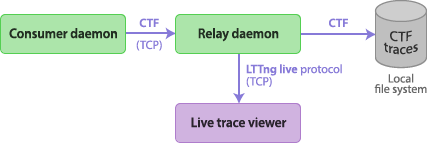
To use LTTng live:
-
On the target system, create a tracing session in live mode:
$
lttng create my-session --live
This spawns a local relay daemon.
-
Start the live viewer and configure it to connect to the relay daemon. For example, with Babeltrace:
$
babeltrace --input-format=lttng-live \ net://localhost/host/hostname/my-sessionReplace:
-
hostnamewith the host name of the target system. -
my-sessionwith the name of the tracing session to view.
-
-
Configure the tracing session as usual with the lttng(1) command-line tool, and start tracing.
You can list the available live tracing sessions with Babeltrace:
$
babeltrace --input-format=lttng-live net://localhost
You can start the relay daemon on another system. In this case, you need
to specify the relay daemon’s URL when you create the tracing session
with the --set-url option. You also need to replace
localhost in the procedure above with the host name of the system on
which the relay daemon is running.
See lttng-create(1) and lttng-relayd(8) for the complete list of command-line options.
Take a snapshot of the current sub-buffers of a tracing session
Since 2.3
The normal behavior of LTTng is to append full sub-buffers to growing trace data files. This is ideal to keep a full history of the events that occurred on the target system, but it can represent too much data in some situations. For example, you may wish to trace your application continuously until some critical situation happens, in which case you only need the latest few recorded events to perform the desired analysis, not multi-gigabyte trace files.
With the lttng-snapshot(1) command, you can take a snapshot of the current sub-buffers of a given tracing session. LTTng can write the snapshot to the local file system or send it over the network.
To take a snapshot:
-
Create a tracing session in snapshot mode:
$
lttng create my-session --snapshot
The event loss mode of channels created in this mode is automatically set to overwrite (flight recorder mode).
-
Configure the tracing session as usual with the lttng(1) command-line tool, and start tracing.
-
Optional: When you need to take a snapshot, stop tracing.
You can take a snapshot when the tracers are active, but if you stop them first, you are sure that the data in the sub-buffers does not change before you actually take the snapshot.
-
Take a snapshot:
$
lttng snapshot record --name=my-first-snapshot
LTTng writes the current sub-buffers of all the current tracing session’s channels to trace files on the local file system. Those trace files have
my-first-snapshotin their name.
There is no difference between the format of a normal trace file and the format of a snapshot: viewers of LTTng traces also support LTTng snapshots.
By default, LTTng writes snapshot files to the path shown by
lttng snapshot list-output. You can change this path or decide to send
snapshots over the network using either:
-
An output path or URL that you specify when you create the tracing session.
-
An snapshot output path or URL that you add using
lttng snapshot add-output -
An output path or URL that you provide directly to the
lttng snapshot recordcommand.
Method 3 overrides method 2, which overrides method 1. When you specify a URL, a relay daemon must listen on a remote system (see Send trace data over the network).
Use the machine interface
Since 2.6
With any command of the lttng(1) command-line tool, you can set the
--mi option to xml (before the command name) to get an
XML machine interface output, for example:
$
lttng --mi=xml enable-event --kernel --syscall open
A schema definition (XSD) is available to ease the integration with external tools as much as possible.
Regenerate the metadata of an LTTng trace
Since 2.8
An LTTng trace, which is a CTF trace, has both data stream files and a metadata file. This metadata file contains, amongst other things, information about the offset of the clock sources used to timestamp event records when tracing.
If, once a tracing session is
started, a major
NTP correction
happens, the trace’s clock offset also needs to be updated. You
can use the metadata item of the lttng-regenerate(1) command
to do so.
The main use case of this command is to allow a system to boot with
an incorrect wall time and trace it with LTTng before its wall time
is corrected. Once the system is known to be in a state where its
wall time is correct, it can run lttng regenerate metadata.
To regenerate the metadata of an LTTng trace:
-
Use the
metadataitem of the lttng-regenerate(1) command:$
lttng regenerate metadata
Important:lttng regenerate metadata has the following limitations:
-
Tracing session created in non-live mode.
-
User space channels, if any, are using per-user buffering.
Regenerate the state dump of a tracing session
Since 2.9
The LTTng kernel and user space tracers generate state dump event records when the application starts or when you start a tracing session. An analysis can use the state dump event records to set an initial state before it builds the rest of the state from the following event records. Trace Compass is a notable example of an application which uses the state dump of an LTTng trace.
When you take a snapshot, it’s possible that the state dump event records are not included in the snapshot because they were recorded to a sub-buffer that has been consumed or overwritten already.
You can use the lttng regenerate statedump command to emit the state
dump event records again.
To regenerate the state dump of the current tracing session, provided create it in snapshot mode, before you take a snapshot:
-
Use the
statedumpitem of the lttng-regenerate(1) command:$
lttng regenerate statedump
-
$
lttng stop
-
$
lttng snapshot record --name=my-snapshot
Depending on the event throughput, you should run steps 1 and 2 as closely as possible.
Note:To record the state dump events, you need to
create event rules which enable them.
LTTng-UST state dump tracepoints start with lttng_ust_statedump:.
LTTng-modules state dump tracepoints start with lttng_statedump_.
Record trace data on persistent memory file systems
Since 2.7
Non-volatile random-access memory (NVRAM) is random-access memory that retains its information when power is turned off (non-volatile). Systems with such memory can store data structures in RAM and retrieve them after a reboot, without flushing to typical storage.
Linux supports NVRAM file systems thanks to either PRAMFS or DAX + pmem (requires Linux 4.1+).
This section does not describe how to operate such file systems; we assume that you have a working persistent memory file system.
When you create a tracing session, you can specify the path of the shared memory holding the sub-buffers. If you specify a location on an NVRAM file system, then you can retrieve the latest recorded trace data when the system reboots after a crash.
To record trace data on a persistent memory file system and retrieve the trace data after a system crash:
-
Create a tracing session with a sub-buffer shared memory path located on an NVRAM file system:
$
lttng create my-session --shm-path=/path/to/shm
-
Configure the tracing session as usual with the lttng(1) command-line tool, and start tracing.
-
After a system crash, use the lttng-crash(1) command-line tool to view the trace data recorded on the NVRAM file system:
$
lttng-crash /path/to/shm
The binary layout of the ring buffer files is not exactly the same as the trace files layout. This is why you need to use lttng-crash(1) instead of your preferred trace viewer directly.
To convert the ring buffer files to LTTng trace files:
-
Use the
--extractoption of lttng-crash(1):$
lttng-crash --extract=/path/to/trace /path/to/shm
Get notified when a channel’s buffer usage is too high or too low
Since 2.10
With LTTng’s C/C++ notification and trigger API, your user application can get notified when the buffer usage of one or more channels becomes too low or too high. You can use this API and enable or disable event rules during tracing to avoid discarded event records.
Example:Have a user application get notified when an LTTng channel’s buffer usage is too high.
In this example, we create and build an application which gets notified
when the buffer usage of a specific LTTng channel is higher than
75 %. We only print that it is the case in the example, but we
could as well use the API of liblttng-ctl to
disable event rules when this happens.
-
Create the application’s C source file:
notif-app.c#include <stdio.h> #include <assert.h> #include <lttng/domain.h> #include <lttng/action/action.h> #include <lttng/action/notify.h> #include <lttng/condition/condition.h> #include <lttng/condition/buffer-usage.h> #include <lttng/condition/evaluation.h> #include <lttng/notification/channel.h> #include <lttng/notification/notification.h> #include <lttng/trigger/trigger.h> #include <lttng/endpoint.h> int main(int argc, char *argv[]) { int exit_status = 0; struct lttng_notification_channel *notification_channel; struct lttng_condition *condition; struct lttng_action *action; struct lttng_trigger *trigger; const char *tracing_session_name; const char *channel_name; assert(argc >= 3); tracing_session_name = argv[1]; channel_name = argv[2]; /* * Create a notification channel. A notification channel * connects the user application to the LTTng session daemon. * This notification channel can be used to listen to various * types of notifications. */ notification_channel = lttng_notification_channel_create( lttng_session_daemon_notification_endpoint); /* * Create a "high buffer usage" condition. In this case, the * condition is reached when the buffer usage is greater than or * equal to 75 %. We create the condition for a specific tracing * session name, channel name, and for the user space tracing * domain. * * The "low buffer usage" condition type also exists. */ condition = lttng_condition_buffer_usage_high_create(); lttng_condition_buffer_usage_set_threshold_ratio(condition, .75); lttng_condition_buffer_usage_set_session_name( condition, tracing_session_name); lttng_condition_buffer_usage_set_channel_name(condition, channel_name); lttng_condition_buffer_usage_set_domain_type(condition, LTTNG_DOMAIN_UST); /* * Create an action (get a notification) to take when the * condition created above is reached. */ action = lttng_action_notify_create(); /* * Create a trigger. A trigger associates a condition to an * action: the action is executed when the condition is reached. */ trigger = lttng_trigger_create(condition, action); /* Register the trigger to LTTng. */ lttng_register_trigger(trigger); /* * Now that we have registered a trigger, a notification will be * emitted everytime its condition is met. To receive this * notification, we must subscribe to notifications that match * the same condition. */ lttng_notification_channel_subscribe(notification_channel, condition); /* * Notification loop. You can put this in a dedicated thread to * avoid blocking the main thread. */ for (;;) { struct lttng_notification *notification; enum lttng_notification_channel_status status; const struct lttng_evaluation *notification_evaluation; const struct lttng_condition *notification_condition; double buffer_usage; /* Receive the next notification. */ status = lttng_notification_channel_get_next_notification( notification_channel, ¬ification); switch (status) { case LTTNG_NOTIFICATION_CHANNEL_STATUS_OK: break; case LTTNG_NOTIFICATION_CHANNEL_STATUS_NOTIFICATIONS_DROPPED: /* * The session daemon can drop notifications if * a monitoring application is not consuming the * notifications fast enough. */ continue; case LTTNG_NOTIFICATION_CHANNEL_STATUS_CLOSED: /* * The notification channel has been closed by the * session daemon. This is typically caused by a session * daemon shutting down. */ goto end; default: /* Unhandled conditions or errors. */ exit_status = 1; goto end; } /* * A notification provides, amongst other things: * * * The condition that caused this notification to be * emitted. * * The condition evaluation, which provides more * specific information on the evaluation of the * condition. * * The condition evaluation provides the buffer usage * value at the moment the condition was reached. */ notification_condition = lttng_notification_get_condition( notification); notification_evaluation = lttng_notification_get_evaluation( notification); /* We're subscribed to only one condition. */ assert(lttng_condition_get_type(notification_condition) == LTTNG_CONDITION_TYPE_BUFFER_USAGE_HIGH); /* * Get the exact sampled buffer usage from the * condition evaluation. */ lttng_evaluation_buffer_usage_get_usage_ratio( notification_evaluation, &buffer_usage); /* * At this point, instead of printing a message, we * could do something to reduce the channel's buffer * usage, like disable specific events. */ printf("Buffer usage is %f %% in tracing session \"%s\", " "user space channel \"%s\".\n", buffer_usage * 100, tracing_session_name, channel_name); lttng_notification_destroy(notification); } end: lttng_action_destroy(action); lttng_condition_destroy(condition); lttng_trigger_destroy(trigger); lttng_notification_channel_destroy(notification_channel); return exit_status; }
-
Build the
notif-appapplication, linking it toliblttng-ctl:$
gcc -o notif-app notif-app.c -llttng-ctl
-
Create a tracing session, create an event rule matching all the user space tracepoints, and start tracing:
$ $ $
lttng create my-session lttng enable-event --userspace --all lttng start
If you create the channel manually with the lttng-enable-channel(1) command, you can control how frequently are the current values of the channel’s properties sampled to evaluate user conditions with the
--monitor-timeroption. -
Run the
notif-appapplication. This program accepts the tracing session name and the user space channel name as its two first arguments. The channel which LTTng automatically creates with the lttng-enable-event(1) command above is namedchannel0:$
./notif-app my-session channel0
-
In another terminal, run an application with a very high event throughput so that the 75 % buffer usage condition is reached.
In the first terminal, the application should print lines like this:
Buffer usage is 81.45197 % in tracing session "my-session", user space channel "channel0".
If you don’t see anything, try modifying the condition in
notif-app.cto a lower value (0.1, for example), rebuilding it (step 2) and running it again (step 4).
Reference
LTTng-modules
LTTNG_TRACEPOINT_ENUM() usage
Since 2.9
Use the LTTNG_TRACEPOINT_ENUM() macro to define an enumeration:
LTTNG_TRACEPOINT_ENUM(name, TP_ENUM_VALUES(entries))
Replace:
-
namewith the name of the enumeration (C identifier, unique amongst all the defined enumerations). -
entrieswith a list of enumeration entries.
The available enumeration entry macros are:
-
ctf_enum_value(name, value) -
Entry named
namemapped to the integral valuevalue. -
ctf_enum_range(name, begin, end) -
Entry named
namemapped to the range of integral values betweenbegin(included) andend(included). -
ctf_enum_auto(name) -
Entry named
namemapped to the integral value following the last mapping’s value.The last value of a
ctf_enum_value()entry is itsvalueparameter.The last value of a
ctf_enum_range()entry is itsendparameter.If
ctf_enum_auto()is the first entry in the list, its integral value is 0.
Use the ctf_enum() field definition macro
to use a defined enumeration as a tracepoint field.
Example:Define an enumeration with LTTNG_TRACEPOINT_ENUM().
LTTNG_TRACEPOINT_ENUM( my_enum, TP_ENUM_VALUES( ctf_enum_auto("AUTO: EXPECT 0") ctf_enum_value("VALUE: 23", 23) ctf_enum_value("VALUE: 27", 27) ctf_enum_auto("AUTO: EXPECT 28") ctf_enum_range("RANGE: 101 TO 303", 101, 303) ctf_enum_auto("AUTO: EXPECT 304") ) )
Tracepoint fields macros (for TP_FIELDS())
Since 2.7
The available macros to define
tracepoint fields, which must be listed within TP_FIELDS() in
LTTNG_TRACEPOINT_EVENT(), are:
Available macros to define LTTng-modules tracepoint fields
| Macro | Description and parameters |
|---|---|
| Standard integer, displayed in base 10.
|
| Standard integer, displayed in base 16.
|
| Standard integer, displayed in base 8.
|
| Integer in network byte order (big-endian), displayed in base 10.
|
| Integer in network byte order, displayed in base 16.
|
| Enumeration.
|
| Null-terminated string; undefined behavior if
|
| Statically-sized array of integers.
|
| Statically-sized array of bits. The type of
|
| Statically-sized array, printed as text. The string does not need to be null-terminated.
|
| Dynamically-sized array of integers. The type of
|
| Dynamically-sized array of integers, displayed in base 16. The type of
|
| Dynamically-sized array of integers in network byte order (big-endian), displayed in base 10. The type of
|
| Dynamically-sized array of bits. The type of The type of
|
| Dynamically-sized array, displayed as text. The string does not need to be null-terminated. The type of The behaviour is undefined if
|
Use the _user versions when the argument expression, e, is
a user space address. In the cases of ctf_user_integer*() and
ctf_user_float*(), &e must be a user space address, thus e must
be addressable.
The _nowrite versions omit themselves from the session trace, but are
otherwise identical. This means the _nowrite fields won’t be written
in the recorded trace. Their primary purpose is to make some
of the event context available to the
event filters without having to
commit the data to sub-buffers.
Glossary
Terms related to LTTng and to tracing in general:
- Babeltrace
-
The Babeltrace project, which includes the
babeltracecommand, some libraries, and Python bindings. - buffering scheme
-
A layout of sub-buffers applied to a given channel.
- channel
-
An entity which is responsible for a set of ring buffers.
Event rules are always attached to a specific channel.
- clock
-
A reference of time for a tracer.
- consumer daemon
-
A process which is responsible for consuming the full sub-buffers and write them to a file system or send them over the network.
- discard mode
-
The event loss mode in which the tracer discards new event records when there’s no sub-buffer space left to store them.
- event
-
The consequence of the execution of an instrumentation point, like a tracepoint that you manually place in some source code, or a Linux kernel KProbe.
An event is said to occur at a specific time. Different actions can be taken upon the occurrence of an event, like record the event’s payload to a sub-buffer.
- event loss mode
-
The mechanism by which event records of a given channel are lost (not recorded) when there is no sub-buffer space left to store them.
- event name
-
The name of an event, which is also the name of the event record. This is also called the instrumentation point name.
- event record
-
A record, in a trace, of the payload of an event which occured.
- event rule
-
Set of conditions which must be satisfied for one or more occuring events to be recorded.
-
java.util.logging -
Java platform’s core logging facilities.
- instrumentation
-
The use of LTTng probes to make a piece of software traceable.
- instrumentation point
-
A point in the execution path of a piece of software that, when reached by this execution, can emit an event.
- instrumentation point name
-
See event name.
- log4j
-
A logging library for Java developed by the Apache Software Foundation.
- log level
-
Level of severity of a log statement or user space instrumentation point.
- LTTng
-
The Linux Trace Toolkit: next generation project.
-
lttng -
A command-line tool provided by the LTTng-tools project which you can use to send and receive control messages to and from a session daemon.
- LTTng analyses
-
The LTTng analyses project, which is a set of analyzing programs that are used to obtain a higher level view of an LTTng trace.
-
lttng-consumerd -
The name of the consumer daemon program.
-
lttng-crash -
A utility provided by the LTTng-tools project which can convert ring buffer files (usually saved on a persistent memory file system) to trace files.
- LTTng Documentation
-
This document.
- LTTng live
-
A communication protocol between the relay daemon and live viewers which makes it possible to see events "live", as they are received by the relay daemon.
- LTTng-modules
-
The LTTng-modules project, which contains the Linux kernel modules to make the Linux kernel instrumentation points available for LTTng tracing.
-
lttng-relayd -
The name of the relay daemon program.
-
lttng-sessiond -
The name of the session daemon program.
- LTTng-tools
-
The LTTng-tools project, which contains the various programs and libraries used to control tracing.
- LTTng-UST
-
The LTTng-UST project, which contains libraries to instrument user applications.
- LTTng-UST Java agent
-
A Java package provided by the LTTng-UST project to allow the LTTng instrumentation of
java.util.loggingand Apache log4j 1.2 logging statements. - LTTng-UST Python agent
-
A Python package provided by the LTTng-UST project to allow the LTTng instrumentation of Python logging statements.
- overwrite mode
-
The event loss mode in which new event records overwrite older event records when there’s no sub-buffer space left to store them.
- per-process buffering
-
A buffering scheme in which each instrumented process has its own sub-buffers for a given user space channel.
- per-user buffering
-
A buffering scheme in which all the processes of a Unix user share the same sub-buffer for a given user space channel.
- relay daemon
-
A process which is responsible for receiving the trace data sent by a distant consumer daemon.
- ring buffer
-
A set of sub-buffers.
- session daemon
-
A process which receives control commands from you and orchestrates the tracers and various LTTng daemons.
- snapshot
-
A copy of the current data of all the sub-buffers of a given tracing session, saved as trace files.
- sub-buffer
-
One part of an LTTng ring buffer which contains event records.
- timestamp
-
The time information attached to an event when it is emitted.
- trace (noun)
-
A set of files which are the concatenations of one or more flushed sub-buffers.
- trace (verb)
-
The action of recording the events emitted by an application or by a system, or to initiate such recording by controlling a tracer.
- Trace Compass
-
The Trace Compass project and application.
- tracepoint
-
An instrumentation point using the tracepoint mechanism of the Linux kernel or of LTTng-UST.
- tracepoint definition
-
The definition of a single tracepoint.
- tracepoint name
-
The name of a tracepoint.
- tracepoint provider
-
A set of functions providing tracepoints to an instrumented user application.
Not to be confused with a tracepoint provider package: many tracepoint providers can exist within a tracepoint provider package.
- tracepoint provider package
-
One or more tracepoint providers compiled as an object file or as a shared library.
- tracer
-
A software which records emitted events.
- tracing domain
-
A namespace for event sources.
- tracing group
-
The Unix group in which a Unix user can be to be allowed to trace the Linux kernel.
- tracing session
-
A stateful dialogue between you and a session daemon.
- user application
-
An application running in user space, as opposed to a Linux kernel module, for example.