Writing babeltrace 2 plugins

This is a write up of Simon Marchi's talk, "Writing babeltrace 2 plugins" that he gave at the Tracing Summit 2019. Links to the video are here, and the slides can be found here.
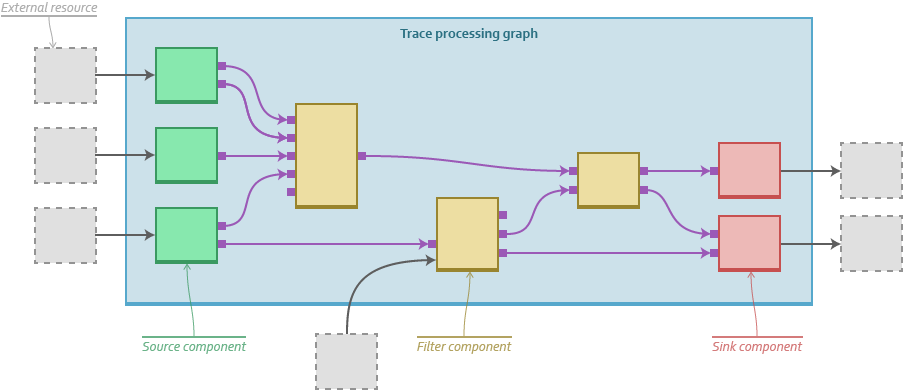
Babeltrace 2 is a framework for viewing, converting, and analyzing trace data. The original Babeltrace project was started in 2010, but over the years developers noticed a number of shortcomings. For one, the Intermediate Representation (IR) was tightly coupled to the Common Trace Format (CTF), and even though the CTF is an expressive trace format used by popular tracing tools such as LTTng and barectf, the goal of Babeltrace was always to support as many formats as possible. The second shortcoming was that the original Babeltrace project didn't have any support for plugins which, again, made it difficult to support new input and output formats.